
Introduction
At WHOOP, we process large amounts of data to deliver on our mission to unlock human performance and Healthspan. Despite staying well below documented rate limits, one of our highest throughput S3 buckets experienced millions of 503 "slow down" errors per month—failures that we wouldn’t have expected to see consistently.
This post details how we reduced these errors by more than 99.99% through a simple yet counterintuitive solution: reversing IDs in our S3 key partitioning strategy. Our successful write requests went from ~99.9% (three nines) to ~99.999999% (eight nines)—a more than 10,000x improvement in error rates.
Background: Data Pipeline at WHOOP
WHOOP securely stores petabytes of data in S3, serving as a source of truth for the member experience, analytics, and ML models. Historically, slight delays in data availability were acceptable due to our hot storage layers handling real-time needs. However, as part of a major architecture redesign, we needed this S3-backed data to be both highly reliable and as current as possible, making even the 0.1% error rate we were seeing unacceptable for our growing scale.
The Problem: Millions of 503 Slow Down Errors
Our original S3 key structure prioritized temporal organization, which seemed logical for our analytics queries:
date=YYYY-MM-DD/id=12345/file_specifics
This pattern worked well initially, but as we were looking to rearchitect other aspects of our system we encountered a critical issue: relatively frequent 503 slow down errors during data ingestion. Despite less than 0.1% of our write requests encountering these S3 server errors, at our scale this translated to millions of monthly failures and retries.
This was puzzling. According to AWS documentation, S3 supports at least 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second per partitioned prefix. We included IDs in our S3 prefix and were definitely making fewer than 3,500 RPS per ID. So why were we consistently hitting these errors?
Understanding Dynamic Partitioning in S3
The root cause lies in how S3 handles partitioning. The documented 3,500 RPS limit is per partitioned prefix. However, S3 doesn't create every possible partition immediately—instead, it dynamically creates new partitions character by character based on observed traffic patterns.
Here's what happens throughout a day with our date-first key pattern:
Start: date=YYYY-MM-DD/* ← Single partition
Later: date=YYYY-MM-DD/id=1* ← Split on first digit
date=YYYY-MM-DD/id=2*
...
Even later: date=YYYY-MM-DD/id=12* ← Further splits
...
The critical issue: When the date changes at midnight, all those fine-grained partitions S3 created throughout the previous day are no longer relevant. The next day started with a single partition for the new day, and S3 had to dynamically split it again.
During high-traffic periods before sufficient partitions existed, we'd hit rate limits and receive 503 errors. We were stuck in a cycle: S3 would eventually partition deeply enough to handle our load, but we'd lose all that partitioning at midnight and start over, hitting 503 errors again once the traffic got high enough.
Evaluating Solutions
The goal was clear: maintain stable partitions across day boundaries while preserving the ability to scale to thousands of requests per second per ID to guarantee we never hit a bottleneck there. We considered several approaches, some of the major ones are outlined below.
S3 Express / Directory Buckets
AWS launched S3 Express One Zone (directory buckets) roughly two years ago as of writing this post. These buckets solve the dynamic partitioning problem by provisioning full throughput from the start: 200k read TPS / 100k write TPS immediately available, with no gradual scaling. Additionally, they offer lower latency and cheaper per-request pricing.
Tradeoffs:
- Storage costs: Significantly more expensive per GB than Standard S3
- Single-AZ durability: Directory buckets only support S3 Express One Zone storage class, storing data in a single availability zone. Our standard storage class provides redundancy across a minimum of 3 AZs.
Much like we never compromise on security or privacy for our members, we also couldn’t afford to compromise on durability. There are ways to mitigate that durability risk with additional architectural complexity, but it wasn't a tradeoff we wanted to make, and ultimately we identified better options for our use case.
ID First Partitioning
The most obvious solution: swap the prefix order to put IDs first.
id=12345/date=YYYY-MM-DD/file_specifics
This would preserve partitions across day boundaries, allowing S3 to maintain per-ID partitions indefinitely and scale up to 3,500/5,500 RPS per ID per day as needed.
Tradeoffs:
- Query pattern impact: This changes which queries are efficient. Instead of "show all IDs that have data for a given day" (efficient with date-first), we optimize for "show all days that a given ID has data" (efficient with ID-first). For our primary workload, this was acceptable—most queries specify both ID and date, and for ad-hoc analytics we have other systems. (Check out our Glacierbase blog post for a look into some of those other systems.)
- Benford's Law problem: The more serious issue. According to Benford's law, naturally occurring datasets often exhibit a logarithmic distribution of leading digits. Approximately 30% of numbers start with "1" while only ~4.5% start with "9".
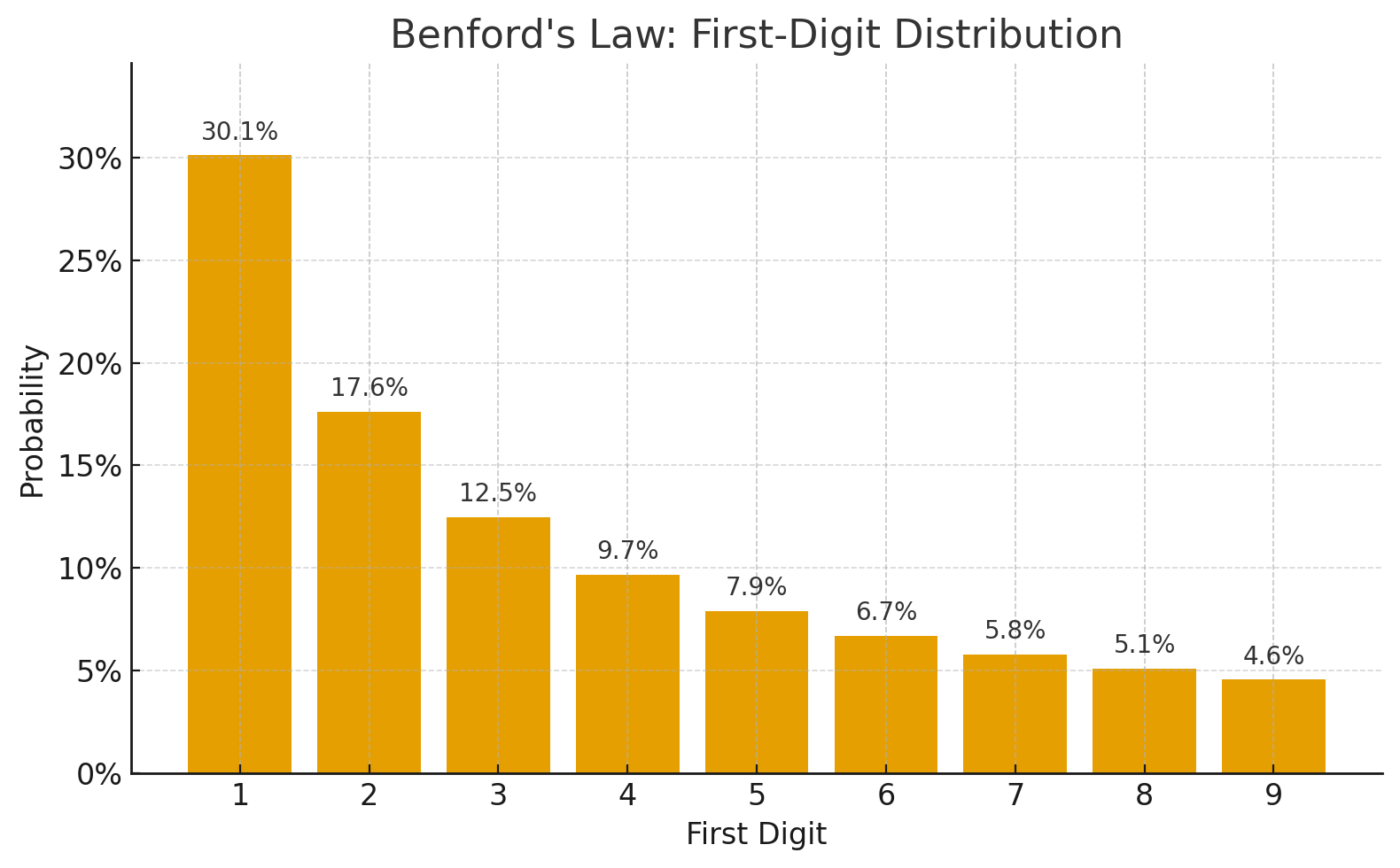 Expected traffic distribution for data split by the first digit according to Benford’s law
Expected traffic distribution for data split by the first digit according to Benford’s law
During normal operation, this imbalance is manageable due to the dynamic S3 partitioning. However, during high-load events—backfills after schema changes, recovery from outages, or seasonal spikes in member activity—the lower-digit partitions would likely hit rate limits while higher-digit partitions remained underutilized. We needed a more balanced distribution.
Hash-Based Partitioning
To solve the Benford's law imbalance, we considered hashing IDs to randomize the leading digit:
id_hashed=a1b2c3d4/date=YYYY-MM-DD/file_specifics
Benefits:
- Perfectly balanced distribution across partitions
- Maintains stable per-ID partitions across days
- Scales to full 3,500/5,500 RPS per ID per day
Downside: The only drawback is relatively minor but worth noting: it makes human traversal of the data nearly impossible. To locate a specific piece of data, you'd first need to compute its hash. While WHOOP engineers rarely need to manually browse S3 keys, we wondered if there was a solution that preserved all the benefits of hashing while keeping keys human computable.
Reversed ID Partitioning (The Solution)
Our final approach is remarkably simple: reverse the ID digits.
id_reversed=54321/date=YYYY-MM-DD/file_specifics
Why this works:
Unlike leading digits, the final digit of numbers in naturally occurring datasets is uniformly distributed—it doesn't follow Benford's law. By reversing IDs, we place this uniformly distributed digit first, achieving:
- Balanced distribution - Each starting digit receives ~10% of traffic
- Stable partitions - ID-first ordering preserves partitions across days
- Full scalability - Maintains 3,500/5,500 RPS per ID per day capacity
- Human-readable keys - Engineers can still navigate the data structure
To find the data for ID 12345, simply look under id_reversed=54321/. No hash lookups, no complex calculations—just basic digit reversal that any engineer can perform mentally during debugging.
Implementation and Migration
Migrating petabytes of production data to a new key structure required careful planning and execution:
- Dual-write period: We began writing new data to both the old and new key patterns simultaneously
- Backfill pipeline: Utilized Lambda and S3 Batch Operations to move and transform existing object keys
- Validation: Verified data integrity and completeness throughout the migration
- Gradual cutover: Transitioned read traffic incrementally to build confidence
- Legacy cleanup: Removed old keys only after confirming all systems operated correctly with the new pattern
The entire migration completed successfully with full data integrity, continuous uptime, an uninterrupted member experience, and minimal operational overhead.
Results
The impact exceeded our expectations:
- Error reduction: Millions of monthly 503 errors → ~50 errors per month
- Reliability improvement: ~99.9% → ~99.999999% success rate (three nines to eight nines)
- Burst handling: A 10x backfill spike caused zero additional 503 errors
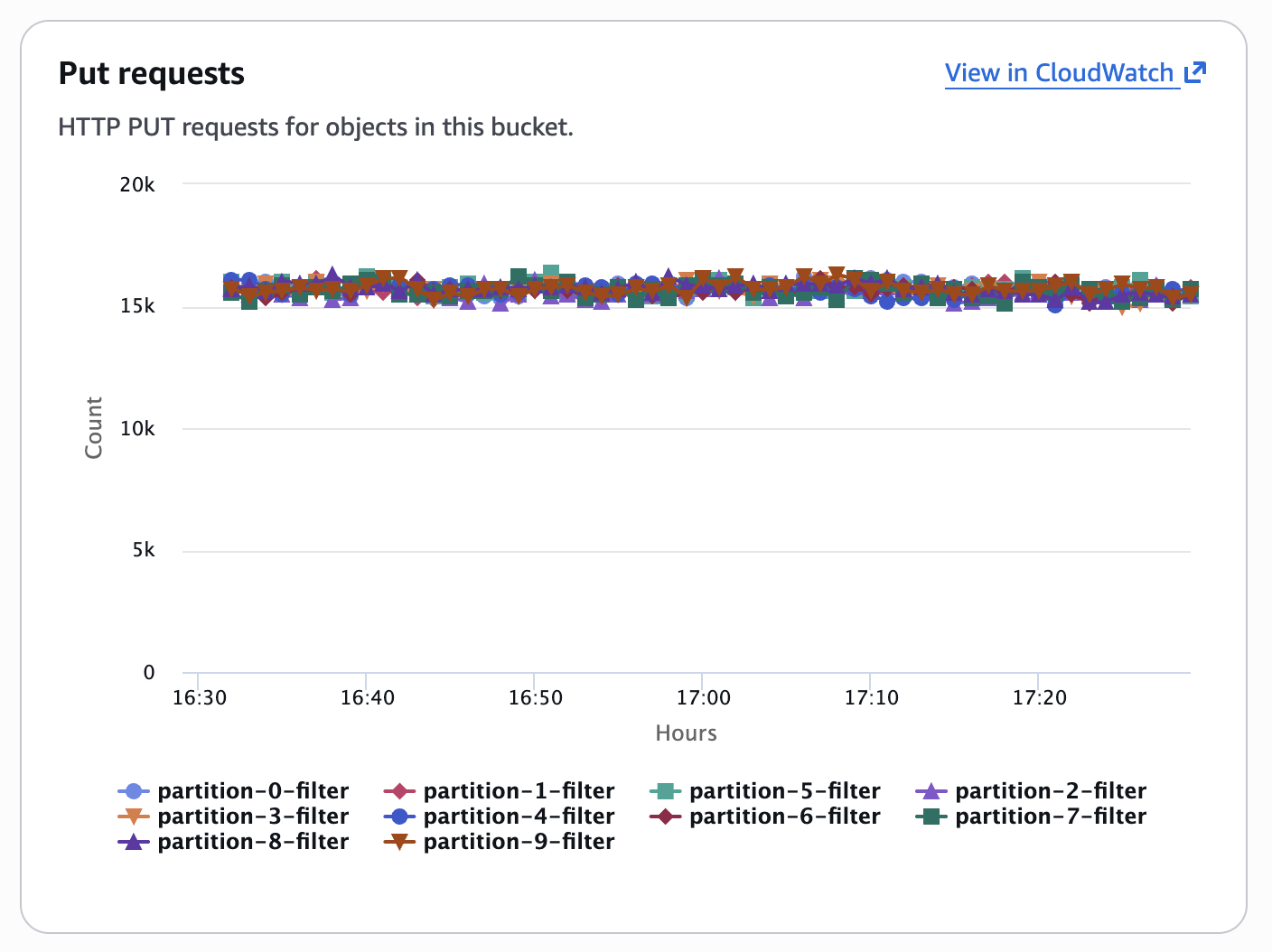 Request distribution across the ten starting digits (0-9) after implementing reversed ID partitioning
Request distribution across the ten starting digits (0-9) after implementing reversed ID partitioning
As shown in the graph above, our request balancing works exceptionally well. Each line represents requests to one starting digit, and their proximity shows balanced traffic. No single partition is overwhelmed, and S3's dynamic partitioning can scale each prefix independently if required.
Conclusion
By understanding S3's dynamic partitioning behavior and applying a simple key reversal strategy, WHOOP achieved a more than 10,000x improvement in error rates—from three nines to eight nines reliability. This required no additional infrastructure costs, no compromise on multi-AZ data durability, and immediately resolved the issue once the migration completed.
The lesson: sometimes the most elegant engineering solutions come from deeply understanding your infrastructure's behavior rather than adding layers of complexity. When facing scale challenges, invest time in understanding the "why" before jumping to expensive or complex solutions.
Interested in solving challenging infrastructure problems at scale? Join the WHOOP engineering team! Check out our open positions.