


A few months ago, we wanted to build a context-aware AI coach, one that could tailor advice based on what screen you're viewing in the WHOOP app. Sleep screen? Recovery tips. Activity screen? Training guidance. Sounds simple, but prompt management was becoming a bottleneck.
The prompts couldn't resolve logic on their own, so logic had to either be wired up in code or left up to the model to figure out: "You are WHOOP, a personal wellness and fitness assistant. If the member is looking at Sleep, do X. If they're looking at Strain, do Y..."
What if the prompt itself could be dynamic? What if we could write modular, reusable prompt components that assembled themselves at runtime?
That's HPML (Hyper Prompt Markup Language), a templating language purpose-built for dynamic, composable LLM prompts.
Hardcoded Prompts Don't Scale
The WHOOP chat-based assistant started as a single AI Agent. Today we run Agents across dozens of domains: workout recommendations, Recovery coaching, wellness insights, and more. As we scaled, we hit several critical limitations:
Static arguments. Want to show a user their workouts from the last 7 days? The prompt can't compute "today minus 7." That date math had to live in application code, and the result was passed in as a fixed value. Every new piece of dynamic data meant another code change.
No conditionals. A user with green Recovery needs different coaching than one in the red. Without conditionals, we duplicated entire Agents for slight variations or packed prompts with verbose "if the member is X, do Y" instructions, which confused the model.
Upfront data loading. Without conditionals, every piece of potential data had to be fetched before rendering, even if the prompt never used it. A prompt that only needed Sleep data for one member context still loaded workouts, Strain, and Recovery, just in case.
No reusability. The same coaching guidelines lived in virtually every Agent. One update meant over a dozen manual file edits. The same branding, tone, and safety instructions were copy-pasted everywhere, and they inevitably fell out of sync.
Serial rendering. Our prompts fetched data during rendering (Sleep stats, Strain scores, Activity history, etc.). Each fetch blocked the next. Data-heavy prompts could stall for seconds before the LLM even saw a token.
You could (and we did) solve a lot of these by constructing prompts in code. But every prompt tweak became an engineering ticket. Every new piece of data required a code change and a full deploy. And the prompt logic became buried in code, challenging for engineers and non-engineers alike to visualize and collaborate on.
Introducing Hyper Prompt Markup Language
HPML brings the expressiveness of a real templating language to Agent prompts. We were already using Handlebars to render objects into readable formats for our prompts, so it was a natural progression to build on that syntax.
The core principle: everything the AI would otherwise figure out mid-conversation, HPML can resolve deterministically at render time. Fetching data, computing a value, branching on a condition, iterating over a dataset. If you'd otherwise leave it to the model or wire it up in code, HPML handles it inline. Here's what it looks like.
Dynamic expressions
Inject computed values inline.
Before HPML:
"Today is " + LocalDate.now() + ". The temperature in " + city + " is " + temperature + " degrees."
With HPML:
Today is {{get_current_date()}}.
The temperature in {{city}} is {{temperature}} degrees.
Smart tool calls with dynamic arguments
The same tools the AI would call mid-conversation, HPML invokes at render time so the data is already in the prompt.
Before HPML:
Use the fetch_weather tool to look up the current weather for the user's city.
Also fetch the evening forecast for tonight.
With HPML:
{{@fetch_weather(city=city date=get_current_date())}}
{{@fetch_evening_forecast(city=city date=get_current_date())}}
Conditional rendering
Conditionals were the game-changer for our context-aware Agent. We expanded on Handlebars syntax with added expression support.
Before HPML:
Consider the following conditions when responding:
- If it is raining, mention the rain and suggest indoor activities.
- If the temperature is above 80, highlight the heat and recommend staying hydrated.
- If the temperature is below 32, warn about freezing conditions and suggest layering up.
- Otherwise, give a standard forecast summary.
With HPML:
{{#if is_raining}}
Mention the rain and suggest indoor activities.
{{#elseif greater_than(temperature, 80)}}
Highlight the heat and recommend staying hydrated.
{{#elseif less_than(temperature, 32)}}
Warn about freezing conditions and suggest layering up.
{{#else}}
Give a standard forecast summary.
{{/if}}
Before HPML, our prompt had to anticipate every possible condition in one giant block. Now the prompt itself adapts. We write focused, clean instructions for each context and share the common boilerplate across all of them through a single maintainable template, with no code changes or application deploys required.
Reusable snippets
A snippet is a standalone block of HPML that gets inserted into the parent prompt at render time. Common instructions like brand voice or coaching guidelines live in one place and get pulled in wherever they're needed.
Before HPML:
<!-- daily-weather-summary-agent prompt -->
You are Sunny, a friendly and upbeat meteorologist...
Format all forecasts as bullet points with highs and lows...
<!-- five-day-analysis-agent prompt -->
You are Sunny, a friendly and upbeat meteorologist...
Format all forecasts as bullet points with highs and lows...
With HPML:
<!-- both prompts -->
{{>meteorologist_personality}}
{{>forecast_format}}
Update a snippet, and every Agent using it gets the change automatically. No more copy-paste maintenance across dozens of Agents.
Loops
Iterate over collections directly in the prompt.
Before HPML:
Summarize this forecast for the user in a readable format.
This week's forecast data:
<!-- data appended with application code -->
[{"date":"Mon","high":75,"low":60,"condition":"Sunny"},
{"date":"Tue","high":68,"low":55,"condition":"Cloudy"}, ...]
With HPML:
This week's forecast:
{{#each fetch_forecast(city=city days=5) as day}}
- {{day.date}}: {{day.high}}°/{{day.low}}° — {{day.condition}}
{{/each}}
This is one of the features we're most excited about. Before loops, summarizing a list of items meant either dumping raw data into the prompt and hoping the LLM figured it out, or building the formatted list in application code. Now the prompt controls its own presentation. Every Agent can call the same data-fetching tools but only render exactly what it needs, how it needs it.
Loops nest naturally too. You can iterate over a week of forecasts and, within each, iterate over hourly conditions. Each iteration gets its own isolated scope, so variable names never collide. The result is prompts that can shape data however they need to without leaving HPML.
Why this matters. HPML prompts are readable. You can look at one and understand what it does without digging through application code. Anyone on the team can spin up or modify an Agent without writing a single line of code. And because prompts are plain text, not application code, ensuring our Agents are safe through security reviews is faster and more thorough. What used to be an engineering bottleneck is now something the whole team can directly contribute to and iterate on.
As a nice bonus, HPML also parallelizes data fetching automatically. A prompt that needs current conditions, a weekly forecast, and severe weather alerts kicks off all three data fetches concurrently. The prompt author just writes {{weather_data}}, {{forecast}}, and {{alerts}}; HPML handles the rest. This took our prompt rendering time down by almost 75% for our most data-heavy prompts.
Faster and Cheaper
We rolled out HPML, with clear boundaries and guardrails, to our context-aware coaching Agent which powers the chat bubble across every screen in the WHOOP app. The biggest performance gain? Fewer tokens.
Token Count
HPML helped us eliminate redundant context. Conditionals mean only the relevant branch gets rendered, not every possible instruction. That alone cut our average prompt tokens by almost 80%.
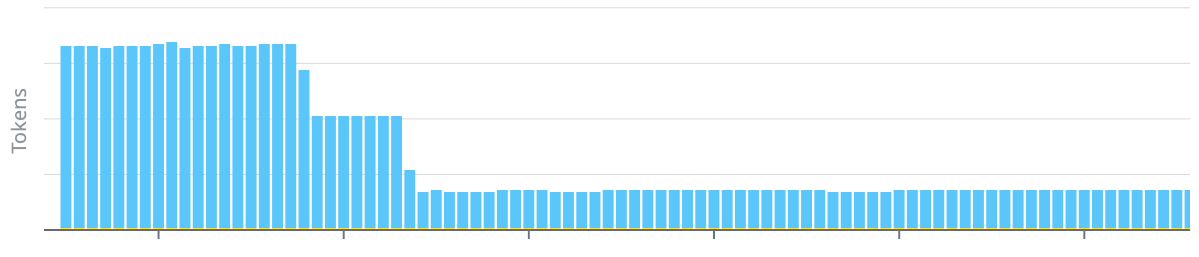
Average prompt tokens fell once HPML eliminated redundant context.
Time to First Token
LLMs must process every input token before generating a response. A 10k-token prompt is fundamentally slower than a 5k-token prompt, no matter how fast our infrastructure is. Fewer tokens also means better caching. Smaller, modular prompts produce consistent prefixes that cache engines can actually hit. Our cache hit rate increased 3.5x, which means the majority of requests skip a huge chunk of token processing entirely. We managed to reduce our time-to-first-token for every response by ~20%.
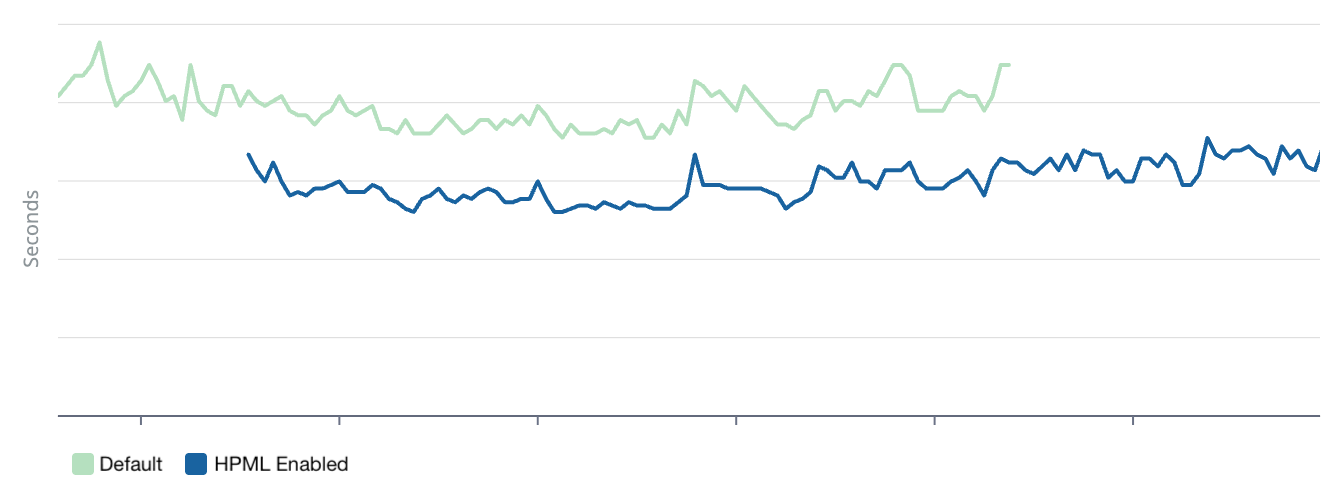
Time-to-first-token improved significantly.
Cost
The cost savings followed directly. Fewer tokens plus better cache hit rates drove overall Agent costs down by ~85%. That headroom lets us invest in more capable models, power more features, and deliver a truly intelligent experience to members.
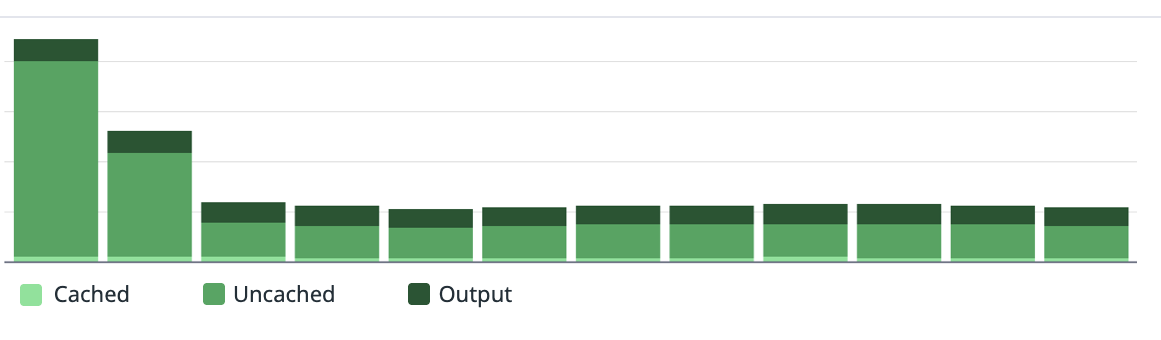
Daily Agent costs dropped significantly after HPML rollout.
The downstream effects went beyond performance. Cleaner prompts with focused instructions produce more relevant responses, driving a 5% increase in the share of responses that members rated positively. New Agents spin up faster with shared snippets for common patterns. Getting new data into existing prompts no longer requires engineering tickets. And non-engineers can read, review, and make changes to Agent prompts directly.
What's Next
HPML is live as the processing engine powering all of our Agents, but we're just getting started. We're exploring switch statements for cleaner multi-branch logic. We're even experimenting with meta-Agents that can write HPML themselves. "I want an Agent that does this" becomes a working prompt.
Prompts are code. They have logic, dependencies, and failure modes. They deserve the same rigor we apply to software engineering: version control, testing, and proper tooling. HPML is another huge step toward treating prompt engineering that way.
Want to build developer tools and infrastructure for AI? WHOOP is hiring engineers who want to solve hard problems at the intersection of AI, language design, and health.