
WHOOP’s Post Mortem process is a structured and blameless reflection tool aimed at learning from and building resilience against incidents. Its current structure fosters team growth, strengthens skillsets, and pushes us forward as a business together.
Purpose of Post Mortems
At WHOOP, we invest heavily in critical moments in which we experience learning moments. We do so with a process called “Post Mortems”. Like many other software companies, these Post Mortems are a meeting focused on how we improve and grow together as a team in an effort to never experience the same incident twice.
This article provides a glimpse into why they are important and how we handle them at WHOOP.
Post Mortems are meetings and presentations triggered after an incident. That incident could range in magnitude from a deployment failing to full downtime. In either event, if it's avoidable and lessons can be shared broadly to grow together as an engineering organization, we make space to perform a post mortem analysis. We analyze the incident with a goal of identifying the following critical components:
- Root cause
- Impact on the customer and business
- Transparent learning and improvement
Post Mortem Principles
Before going into the structure of our Post Mortems, it is important to set some ground rules for performing a post mortem to maintain a culture oriented and invested in learning and growing together. Here are the principles we have found work well and are repeated in a slide at the top of every Post Mortem presentation:
- Ask why - we are here to ask why first and foremost, in pursuit of learning.
- Be blameless - this means no names, no team names. Everything in these conversations is a collective “we”, never individualistic.
- Learn and build resiliency from failure - we grow stronger together in these moments, embrace it, and grow together hand in hand.
- Infuse all learnings and any tooling yielded from the event to everyone.
See how we achieve the above outcomes using these principles below.
Post Mortem Meeting Structure
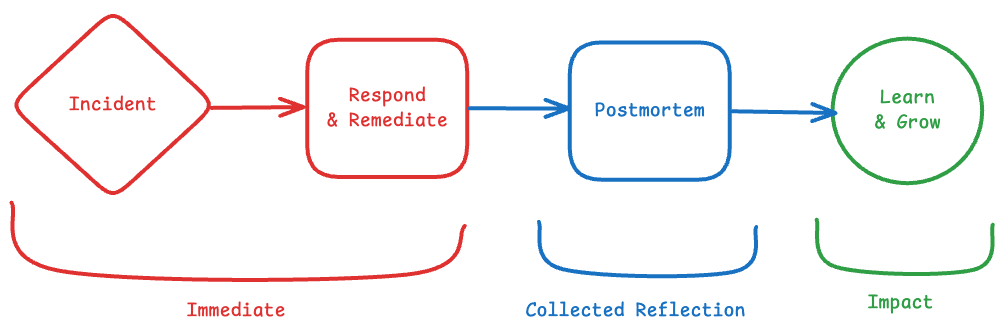
Flow from incident to accomplishing learning
The Post Mortem meeting starts with an internal post mortem slide deck that prompts the coordinator to drive through a structured experience that we have built up over years of experience. Anyone can call for a Post Mortem at WHOOP as long as it's aimed at growing ourselves for the better.
1. What & Impact
Our very first part of the process involves documenting what happened. In a few high-level sentences, describe the incident in customer or business impact terms. i.e., “X customers experienced a mobile crash resulting in the customer having to reboot the application from 1/1/2025 9:00am - 1/2/2025 9:00am”
This succinct description accomplishes communicating clearly what the impact was, who was impacted, when it occurred, and for how long. In just the first slide, you have built and communicated an executive summary. This summary will also serve you well in the future when you need to look back and search through Post Mortems of the past.
We also utilize internal metrics that rate the severity of incidents to indicate if the team is in a healthy state, or a state in which they need to drop roadmap work and focus on operationally getting back on track - we call such a state “code red”. A good live indicator for this is page and incident volume, but these Post Mortems provide an additional checkpoint to ask ourselves, “Do we need to take a step back here?”.
2. Timeline
The second section is building out a timeline of how we got to the point of the incident. This timeline includes everything relevant leading up to the incident that contributed to the culmination of the impact being incurred.
It is important to build a comprehensive timeline that will serve as input into later sections that provide solutions for next steps and implementation. Driving clarity in the timeline is crucial when presenting. We encourage people to pause the presentation and ask timeline questions if they are not clear.
3. Root Cause & 5 Whys
We utilize a methodology called the 5 Whys to drill down to the real root cause. Essentially, we ask why the incident happened in repeated succession until we get to the underlying root cause. This practice influences solution spacing aimed at addressing the underlying problem rather than coming out of a meeting with band-aids that patch symptoms. We have found that if you do not orient the conversation here, you will ultimately be back in the same meeting running a Post Mortem on the same topic from repeated mistakes.
4. Data
If you are not backing up both the impact and root cause with data, there's no foundation to stand on. Include your data to back up your emphasis on the criticality, impact, and rationale. Here are some examples of data you could include:
- Datadog dashboards representing the systematic indicator or impact i.e. Latency graphs, or error rate graphs.
- Metrics on customer usage in the domain of the incident.
- Dollar figure calculations on sales volume or rate of check outs on your ecommerce site.
No matter the metric you chose, utilize one or two to illustrate the impact of the incident.
5. Post Recovery Remediation (immediate)
It is worth taking a moment after alignment on the root cause to talk about what remediation actions were taken during and right after the incident, so as to avoid a re-hashing of already completed action items. Clean up work is also important to discuss to make sure you return to business as usual. An example might be reversing a scaling action that was a temporary mitigation to avoid unnecessary costs long term. You will find that the processes taken and documentation can be improved upon when you take the moment to reflect in this section.
6. Operational Excellence
This section is crucial to ideating on what action items need to be taken away from this meeting. It focuses on three main operational excellence concepts:
- Prevention (most important) - Aimed at the ability to catch or prevent the incident from going out the door and impacting the customer. For example, think about how we could create a test to catch the incident early in the development lifecycle or a guardrail to block it from happening ever again.
- Detection - Aimed at reducing the time it takes to detect an incident after it is out the door. Ask yourself, how can we know about this incident before our customers know?
- Mitigation - Aimed at reducing the mean time to resolution for the next incident. Ask yourself, what can we do better to prepare our response in the moment?
7. Action Items
Here, we take what we learned in the Operational Excellence section and assign owners whose responsibility is to go and execute on these actions, all aimed at preventing experiencing the same Post Mortem ever again. These items should be immediate and actionable. Sometimes, they may be discoveries of what is possible and require follow-on decisions, but there needs to be a clear short-term start to each action item.
8. One Key Learning & Sharing
Our last section of the Post Mortem boils down the meeting into 1 to 2 sentences that represent the key lesson and learning point from the incident. This is bundled into a departmental wide email from the person driving the meeting, along with a link to the Post Mortem presentation for transparency. We encourage folks to ask questions or follow up in that same email thread. We aim to infuse and share all learnings, no matter the incident, with every engineer at WHOOP so that we can learn and grow together as one team.
I hope the transparency and structure of this process helps other organizations out there start on a journey of investing in reflection and growth from operating software at scale.