
MCP! It’s everywhere and it's confusing. In my opinion, the usual explanations of “it’s like a USB-C adapter” assumes a certain level of proficiency in this space. If, like me, you have been struggling to keep up with the AI firehose of information and hype, this article is for you. It is a gentle introduction to MCP and all things AI so you can understand some key terminologies and architectures.
This was originally an internal company talk that I gave twice: once for a technical audience and once for a non-technical audience. At the recently concluded Whoop Hackathon, MCP servers sparked a lot of discussion. Some participants were all-in, while others had barely heard of them. So I felt like this topic is a great addition to our blog for internal users and the engineering community as a whole. We will cover some fundamentals and move on to what MCPs are and what problems they solve.
For easy skimming, I have split this article into three sections corresponding to the MCP acronym: Model, Context and Protocol. We will dive deep into the Model part because that is the basis for everything and we will touch on the other parts later in the article. If listening to a podcast is more your style, I highly recommend this episode from ConTejas Podcast. Let’s get started!
Model
Before we can answer what an MCP is, let’s take a step back and answer what a Model is. A Large Language Model is a neural network that is trained on a large amount of documents. You can imagine this as a slice of all the documents on the internet ranging in petabytes. This 1-hour talk Intro to LLMs by Andrej Karpathy goes into great detail on what goes into building an LLM and I highly recommend watching it. This slide from his talk captures the essence of LLM creation. You feed the training data to GPUs over several days to create a large language model.

Source: Intro to LLMs by Andrej Karpathy
Training
The process is the training step. You ask the model a question like “who let the cat out of the ___” and ask it to predict the next word. It would make attempts and mistakes, and you would train it over and over until you get a desirable answer. Over a period of time, the neural network becomes good enough to reliably answer most commonly asked questions.
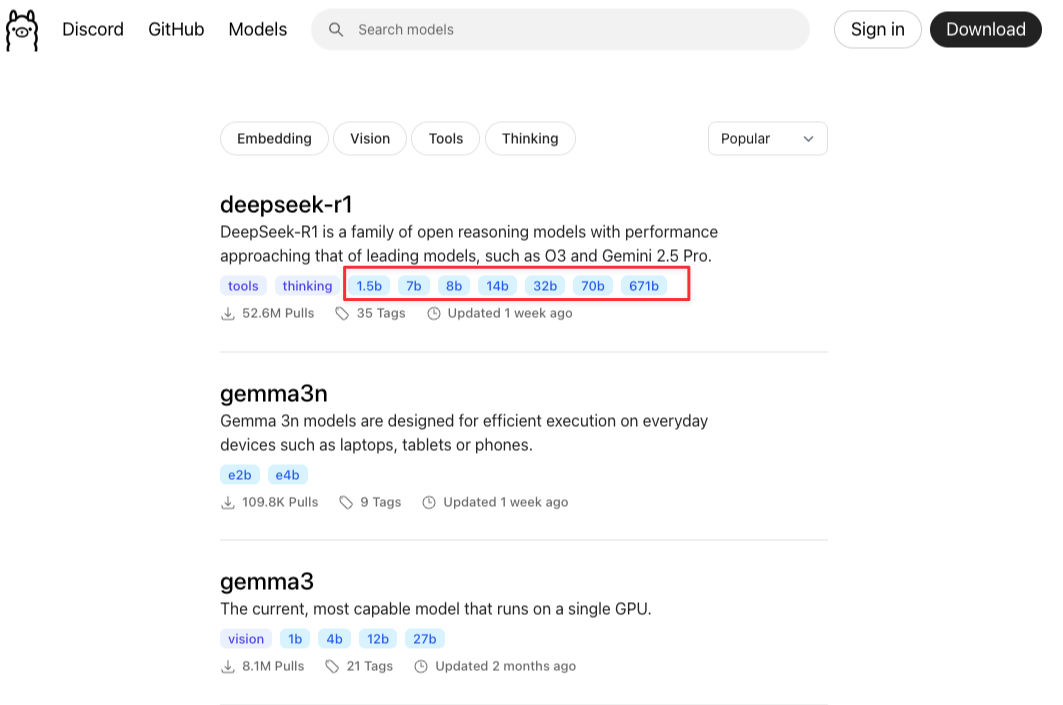
The technical term for the output is “parameters”. The training adjusts the parameters within the neural network to provide the right response. If you are a developer, you can think of these as if..else statements that control the flow of your program. Here, these parameters control the flow of the output generation.
An interesting thing to note is you train the network as a whole and don’t get to fine tune the parameters individually. This is because the parameters can range in billions. If you look at some open source models, they will tell you how many parameters they contain. If you visit the Ollama site and search for models, it will show you some open source models with as many as 671 billion parameters. The higher the parameters, the better the quality of output but also, the more resource-intensive to run.
Fine-tuning / Assistant mode
When you train a model on internet documents, it is only good at generating look-alikes of internet documents. We know you can ask ChatGPT to give you an answer in a specific format like “under 200 words”, “don’t use emojis” and it is able to understand and respect that. This step is called finetuning in the LLM creation process and this is what enables a model to behave like an assistant. This takes the text generation one step further as it tailors the response to users’ specific needs.
In the finetuning step, we stop providing more data to train the model and instead focus on helping it become a better assistant. This happens mostly through trial and error, meaning given a request, does the model perform accurately or not. This information is provided back to the model to continue developing its assistant capabilities.
With all of this information, you now understand what the heck a GPT is.
- Generative - it can generate text based on its training data
- Pre-trained on a large set of data
- Transformer - this is an architecture for LLMs
Transformer architecture

It is helpful to understand the transformer architecture so you know how the heck an LLM works.
Tokenization
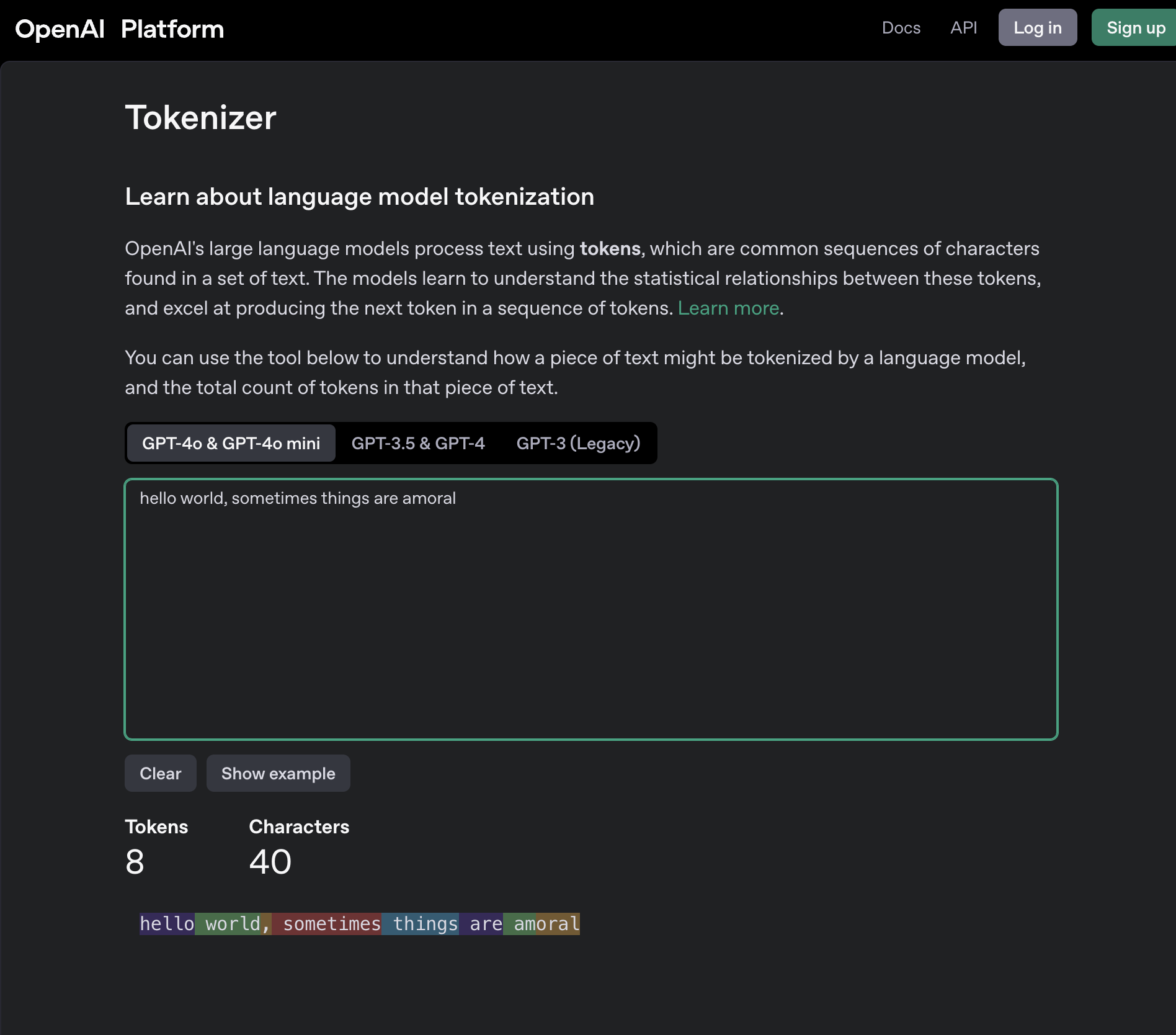
A token is the smallest unit of text an LLM can understand. Each model tokenizes differently but you can use this online playground to see how sentences are tokenized. The tokenizer in the LLM splits the input into tokens, then uses an internal vocabulary that maps tokens to IDs because computers work better with numbers. All words are converted into numerical representations. For example, the sentence “hello world, sometimes things are amoral” is converted to a numerical representation like [24912, 2375, 11, 10069, 3283, 553, 939, 16882].
Multi-headed self-attention
The concept of attention is not unlike the human concept of attention - being able to focus on something. In LLM parlance, it refers to the LLM’s ability to read raw user input and convert it into distributed representations.
The idea of multi-headed is that the model can read the user input, not top-to-bottom, not bottom-to-top but in parallel – with multiple heads. This is what allows LLMs to read a large volume of text in a short amount of time.
Vector embeddings
A vector is a numerical representation that contains 2 pieces of information - weight (the value assigned to it) and direction (positive or negative). A good way to understand this is through the latitude and longitude coordinate system we use for places. If I give you the below 3 coordinates, you would be able to find the distance between them and also determine which of the 2 places are closer to each other: -34.6037, -58.3816 (Buenos Aires, Argentina) -12.0464, -77.0428 (Lima, Peru) -33.4489, -70.6693 (Santiago, Chile) Similarly vector representation of words can use the weight and direction of vector embeddings to determine which words are more related to each other. In the below example, man is closer to a living being than a feline and you can see how this is represented numerically.
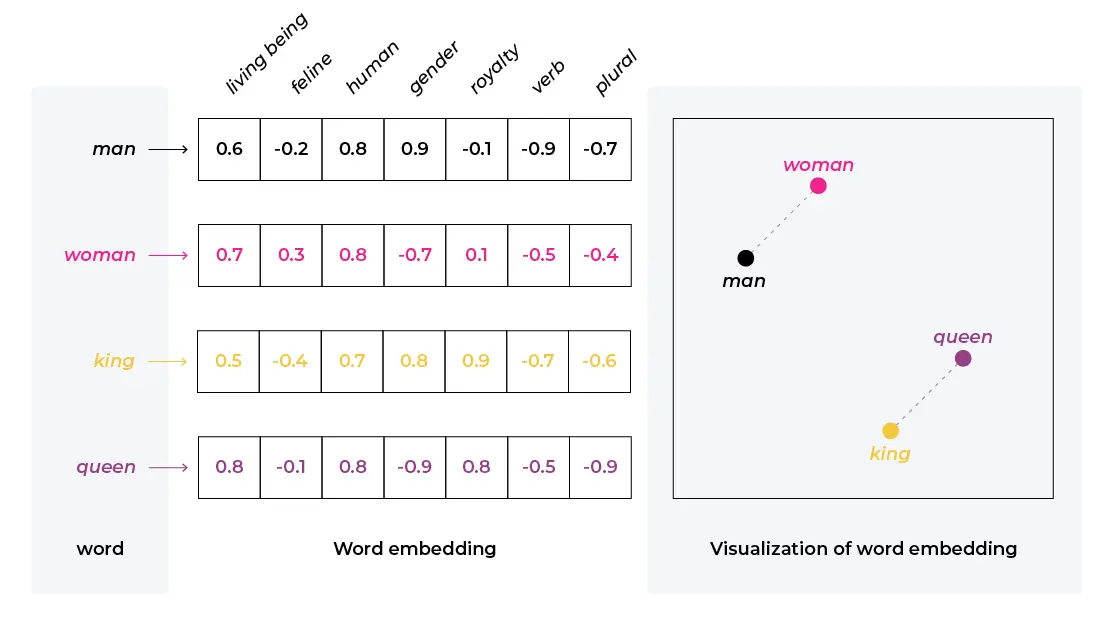
Source: Vector Embeddings
These examples are clearly 2 dimensional but the spatial representation of an LLMs vocabulary can have 1000s of dimensions. The LLM uses the token ID representations to spatially locate words that are closest in semantic meaning to the input word. It does this one word at a time and uses this search to predict the most likely next word. This is why you see LLMs stream text responses because they are generating one word at a time.
Auto regressive
Not only is the model generating one word at a time, but also at each step, it is able to take the output it generated in the previous step and use that in addition to the user’s query to enhance the quality of its output. This is how it is able to generate full emails and tech plans because it also has the information of what word it has just generated.
So really an LLM is a fancy autocomplete with some bells and whistles. To gain a deeper understanding of how LLMs work you can view this video that shows a good graphical explanation.
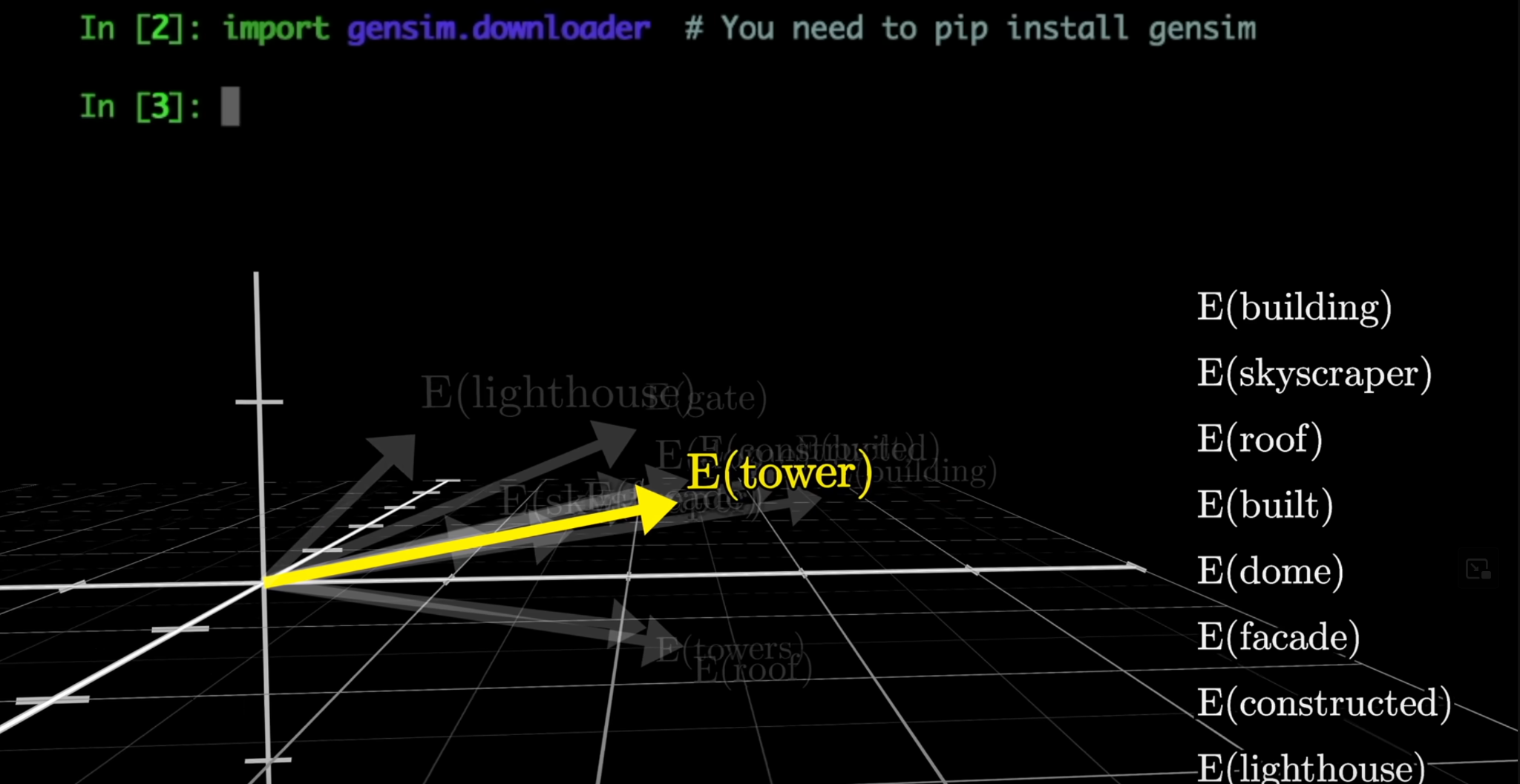
Source: Multi-dimensional vector embeddings
Advantages of LLMs
LLMs are really good at enabling a form of computing that wasn’t previously possible. Usually, computers are very limited by the syntax in which you can communicate with them. LLMs now unlock the ability to converse with a computer using natural language. It is a new wave of computing for a computer to be fault tolerant and understand what you mean without forcing you to use a small set of vocabulary.
Limitations of LLMs
- Hallucinations - I am sure you have all had an experience where the LLM hallucinates, and quite confidently so. This is a big limitation of this technology but will get better over time.
- Bad at math - because internally what it is doing is a semantic search and finding words related to each other, it’s famously bad at math and facts.
- Non-deterministic - The way LLMs work is non-deterministic, meaning, for the exact same input given to it multiple times, it would provide varying outputs
- Training cutoff - perhaps the biggest limiting factor to how useful an LLM can be is the date in which training is cut off. If you ask it “who won the game last night” it will not be able to get this information from its memory.
Context
One way to overcome the limitation of training cutoff is to release more models. This way you can keep updating the model data to be more accurate but there will always be a catch up period.
The other limitations bring us to the idea of a context. To ensure the LLM is providing valuable output, you provide more “context”, which is additional information to help steer the LLM in the right direction.
Prompting
The easiest way to provide more context is to prompt better. This is why you see examples of good prompting to ask the LLM to assume a role like “You are a senior engineer” or “You are a copywriter” - these help narrow down the model’s response space. Throwing it as the first part of your prompt helps move the generation part to a narrower space. When someone says they created a “custom GPT” they are prompting the GPT to behave in a certain way by giving it a prompt that will narrow down its responses.
Tool use
To overcome problems where the LLM does not have information in its memory, we can enable tool use. A tool is any program the LLM can call that can reach outside of the LLM for additional context. Internet search is a tool that most LLMs can now use to answer questions that cannot be answered from memory alone. The tools provide additional data and the LLM is still responsible for consuming it and generating a response.
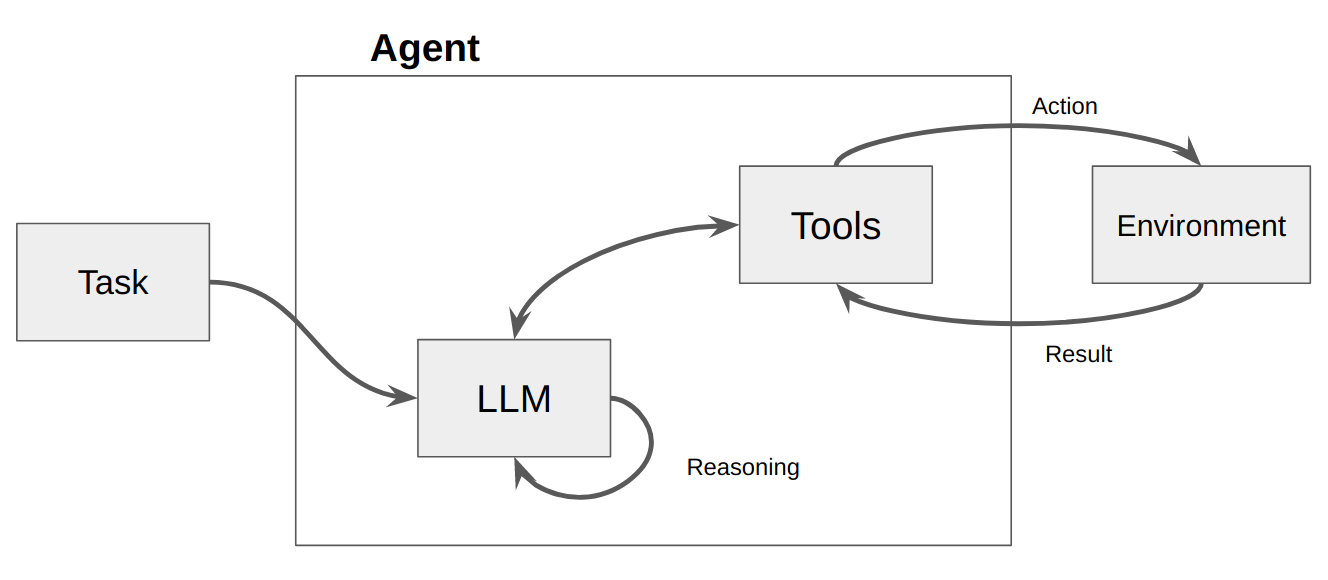
Retrieval Augmented Generation
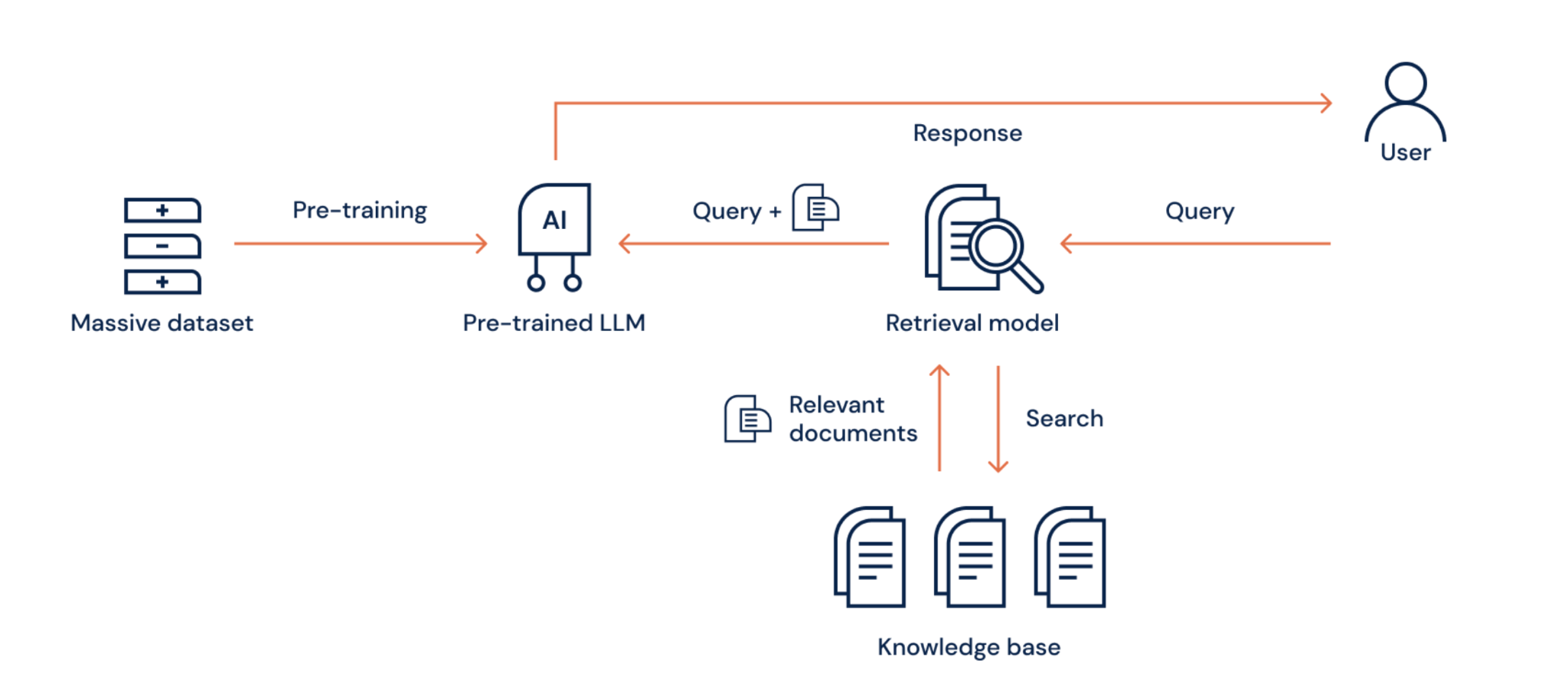
In some cases, the information you want to provide an LLM might not be publicly available. For example, if you want the LLM to access a user's health data, this will likely be stored in a proprietary database. This is where RAG comes into play. RAG stands for retrieval augmented generation, which, as the name sounds, provides additional context before generation begins. Private data can be converted to vector embeddings so the model can use that as additional information before generating a response. This hybrid architecture combines the text generation powers of an LLM with accurate data in context of the query.
Protocol
Now that we have an understanding of a Model and what Context is, let’s look at what a protocol is. A protocol, in general, is a set of rules that define how data is formatted, transmitted and processed between computers. It’s a spec that defines how computers talk to each other. Hyper Text Transfer Protocol (HTTP) is the underlying protocol that defines how a client (browser) can communicate with a web server. Similarly, MCPs are also a two-system architecture with a client and a server.
Providing superpowers to LLMs
By now it is also clear that LLMs are good at generating text but not much else. When most people talk about being excited about AI, they are talking about Agentic AI, which means the AI system is capable of not just generating text but performing actions like making a purchase, writing to file system or adding calendar events. In order to provide this ability, we need LLMs to be able to talk outside of their environments to do two things:
- Fetch data - we already covered how this works
- Perform actions - This is the capability that MCP unlocks.
MCP stands for Model Context Protocol and is one of the first protocols proposed to standardize the way LLMs can talk to external systems. Some popular MCPs in the web development world include the Github MCP, Jira MCP and Figma MCP. When you add these MCPs to your LLM agent, they get added as tools for the LLM to invoke.
In VS Code, if you add the Github MCP and click the tools icon in your AI chat, it will list all the capabilities this MCP provides. When an MCP provides a function like “add_issue_comment” to the LLM, you can now use natural language to tell the LLM to “can you add a comment in PR#2695 to write tests” - the LLM understands it needs to invoke this specific function within the tool and is able to make the function call with the text you provided as parameter.
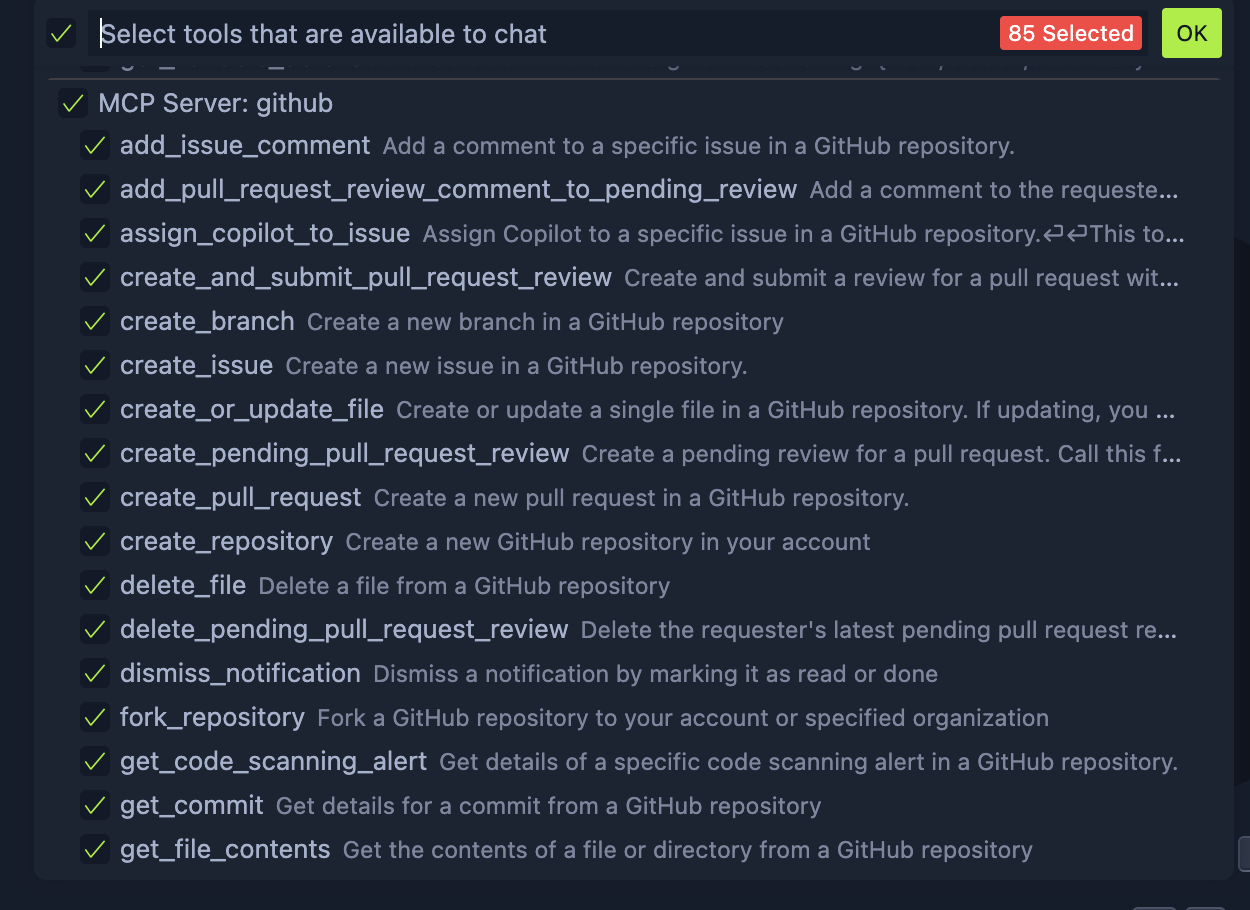
Most current implementations of MCPs are a thin wrapper around existing REST APIs but over time, we will start noticing how the function calls start shifting as clients start querying data in more fluid ways through natural language than is possible through REST. It is by nature stateful so you can share context from the conversation with the servers and it uses JSON-RPC for remote procedure calls to facilitate the communication.
You can also extrapolate and see how multiple MCP servers can enable autonomous workflows. Being able to provide a link to a figma design and asking an agentic code editor like Cursor to implement it and create files as needed and make a pull request with these changes all from a chat prompt is powerful. The future of user agents will be more like chat as the center with tools being pulled in as needed. This truly marks the beginning of a new era in computing.
Why MCPs are exciting
We’re living through a paradigm shift in computing, one where natural language becomes the new programming interface. AI, particularly in the form of large language models, has opened up a world where humans can interact with machines in a more intuitive and expressive way. No more rigid syntax or steep learning curves. That alone is powerful, but MCPs take it further. They transform LLMs from passive responders into active agents capable of doing things like fetching data, manipulating files, updating tickets, even coordinating across tools like GitHub, Jira, and Figma.
It’s still early, and like all new protocols, MCP is evolving fast. But the vision is clear: a future where LLMs are not just chatbots, but fully-integrated collaborators in your digital workflows. I hope this breakdown has helped demystify what MCP is and why it matters. If you’ve made it this far, thanks for reading. Feel free to reach out with any questions or comments!
References
I highly recommend these resources to continue your journey to understanding MCPs and LLMs