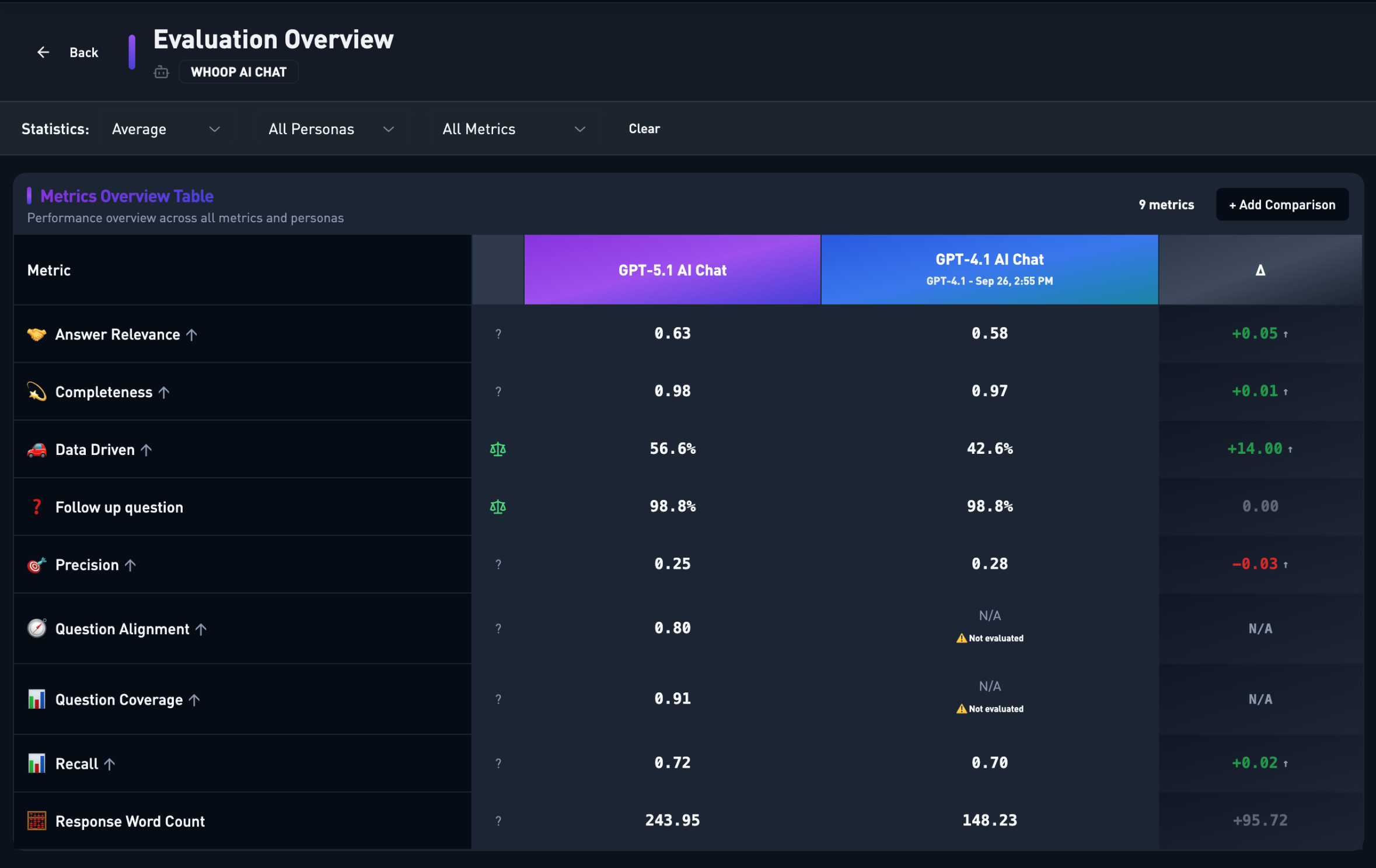
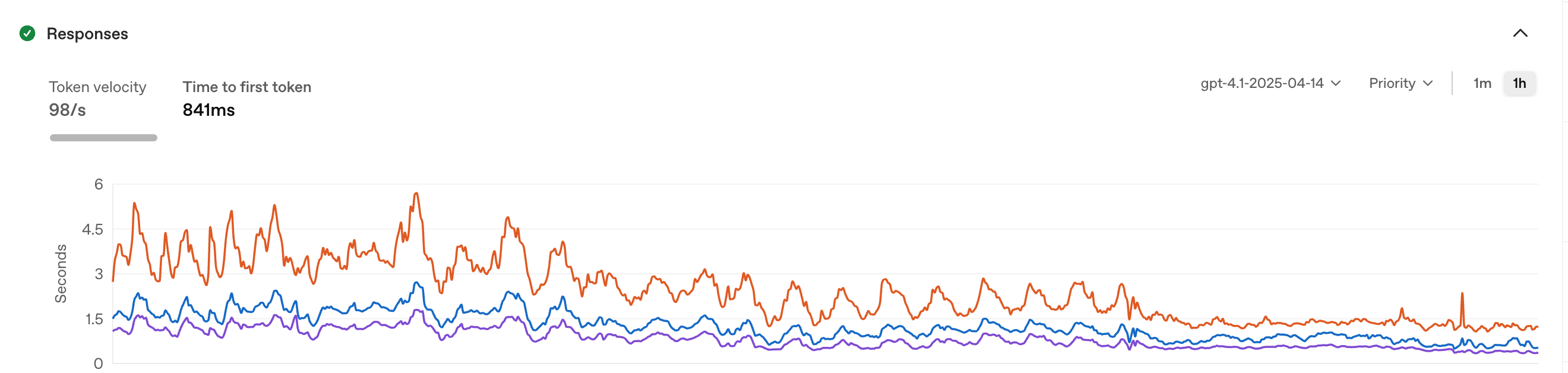
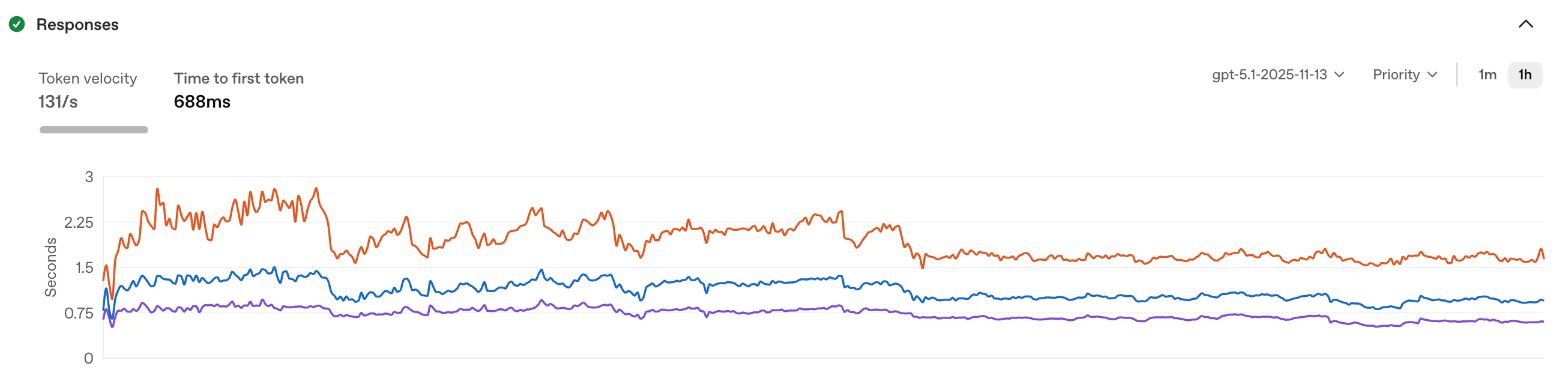
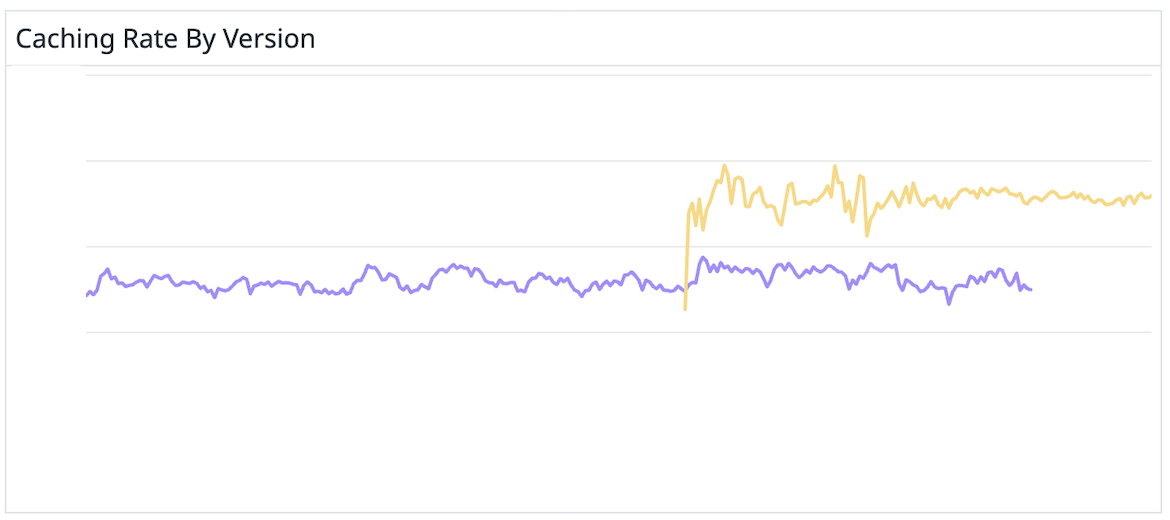
Across the industry, we see AI features shipped on hope alone. At WHOOP, we ship with data and security in mind. In order to support over 500 unique agents, we built an evaluation framework that treats LLMs like the statistical, noisy systems they are. Here's exactly how it works.
The Problem
We've built AI Studio to enable anyone at WHOOP to develop and interact with our homegrown Agents, resulting in an explosion of more than 500 of them across virtually every screen in the app. But as we reduced the friction to build Agents, the new bottleneck became testing them. Manual dogfooding turns into an endless game of whack-a-mole. A new Agent might work well for most cases, but for some percentage of events, it might save incorrect dates or store trivial information that doesn't add member value. And once we identify a problem, prompt-tweaking doesn't tell us if it's truly fixed or just in the cases we manually tested.
The underlying truth is that an LLM is a statistical, non-deterministic machine: you cannot test it like traditional software. You MUST track true and false positives, error rates, and acceptable failure thresholds at scale. That's what we built.
Starting Small, Then Scaling
We started humbly two years ago in spreadsheets, creating thousands of test questions, expected answers, and synthetic "Personas" (reproducible synthetic data with profiles like an IN_THE_GREEN member with 15 Green Recoveries above 80%). This spreadsheet-driven framework supported our team and our singular main Agent for over a year, but it was painful as we hit the functional limits of the spreadsheets and inflexibility of the hardcoded metrics we had created. And as the number of Agents exploded, we needed something that could scale.
The Next Generation
To solve these scaling problems, we built a dedicated evaluation platform directly into AI Studio, our internal tool for building and managing secure Agents.
This new framework moved us away from static spreadsheets and into a dynamic, integrated workflow. Now, instead of copy-pasting rows, we can:
- Define Input Sets: We needed complex inputs to simulate real members' interactions. We built a service to create synthetic member templates called "Personas", with different data profiles. We developed a tool to simulate back-and-forth conversations with an agent. Inputs can also just be text and images and optionally include the expected ground truth answer, but combining all of these forms a complex Input Set which can be reused across different Agents.
- Run Evaluations on Demand: With a single click, an Engineer or Product Manager can run a full suite of tests with a new prompt version.
- Customize Metrics: Anyone can design a new metric easily using a robust list of metric types, both LLM-based and traditional text analysis. These metrics vary from validation that a response includes a follow-up question or that the data in the response is correct or whether a sub agent/tool has been called in creating the response. These all help maintain a high level of quality and security across our agents!
- Analyze Results in Real-Time: Aggregated metrics results and individual trace-level details are available immediately, allowing for rapid iteration cycles. The results can be filtered and parsed to identify exactly where the agent fell short and where it excelled!
This unlocked fast, repeatable evaluations for every Agent we ship, ensuring that we weren't just "feeling good" about a change, but actually measuring its impact and enforcing testing and security gates before anything reaches members. This was crucial for our big feature rollout: Memory.
An Example Evaluation: Memory
We have an LLM Agent which saves memory "nuggets" as a member interacts with WHOOP in the app. The goal is to accumulate individually personalized context for WHOOP to reference wherever it may be valuable. On every message from the member, the Agent asks, "Is this worth remembering? If so, remember it." The Agent will store the memory, along with any 'start' and 'end' dates it was able to derive. We then pull any generated context into WHOOP for every conversation in the app. We filter based on 'start' and 'end' dates, only pulling in 90 days' worth of context, and if there is no date associated, we pull it in "just in case."
Before rolling this out to members, we used our new Evaluation platform to stress-test the Agent and make sure it was ready.
Discovering the Issue
During pre-launch testing, we discovered the Agent was too ambitious. Left unchecked, it would have:
- Saved memories on nearly every interaction, most without 'start' or 'end' dates -- meaning they'd accumulate indefinitely.
- Stored context nuggets that weren't remembering anything important -- not useful as personalization.
Given these problems, we decided to spin up an Evaluation.
Creating Metrics
We used a recall-style metric (how often we saved what we should have saved) to compare the ground truth of what we expect to be saved to what is actually saved. For new metrics, we needed to create some LLM-as-a-judge and tool-calling verification metrics to confirm that this Agent's results matched our expectations.
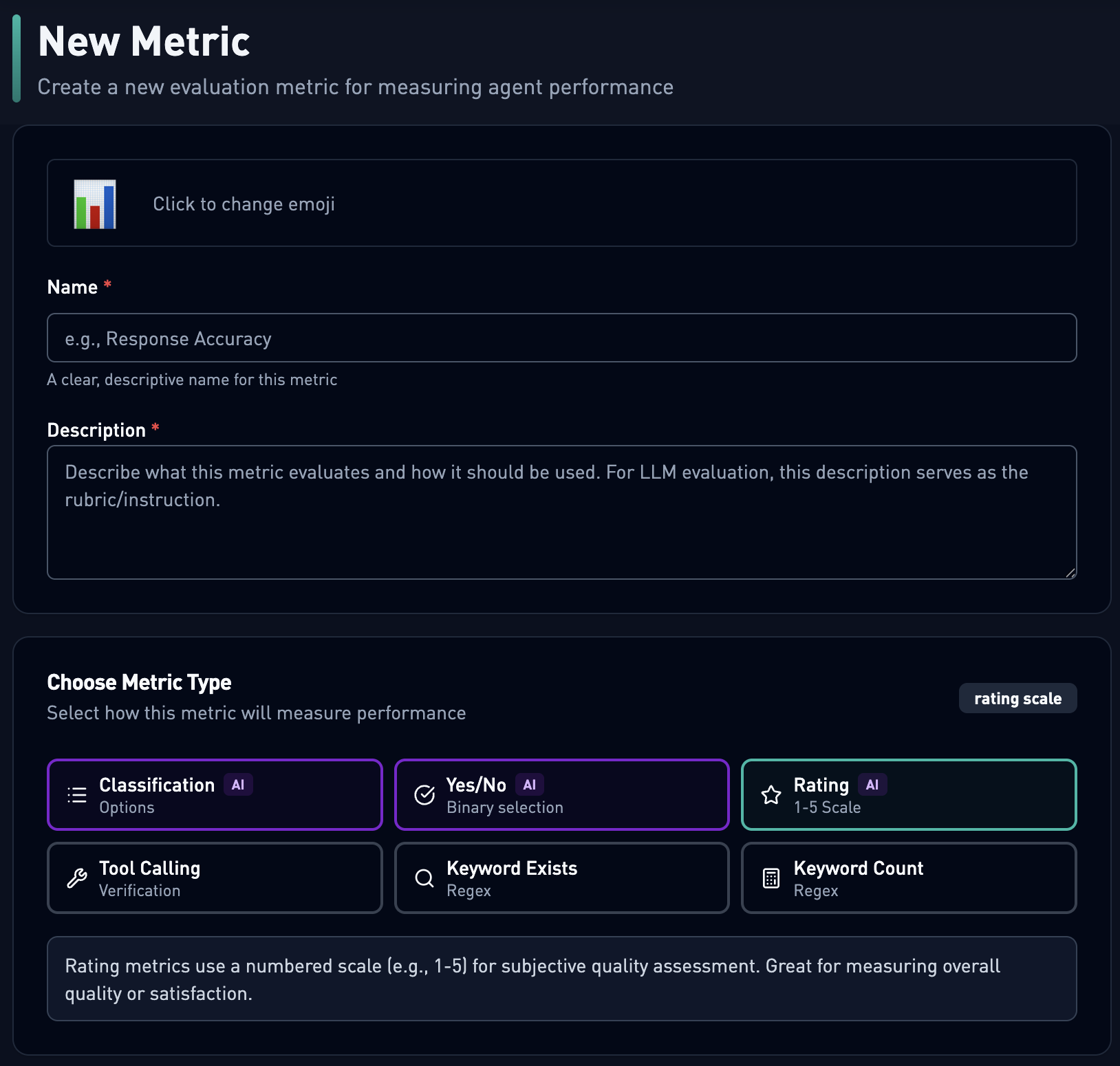
Example metric to show creation. We support a LLM-as-a-judge, and a variety of pattern matching across different message types.
An anonymized selection of real questions from our team (expanded with AI assistance) gave us hundreds of questions covering member queries in three categories:
- Definitely should be remembered ("I am training for a half-marathon in November")
- Definitely should NOT be remembered ("What was my Recovery score this morning?")
- General questions ("Is WHOOP waterproof?")
We then went through and created expected behaviors (ground truths) for each of these questions. This allowed us to evaluate Should Save Context Rate: Should the Agent save something? What should the Agent have saved?
Getting a Baseline
With some metrics created, we ran an initial baseline against the unreleased Agent and confirmed what we suspected: Memory wasn't ready to ship.
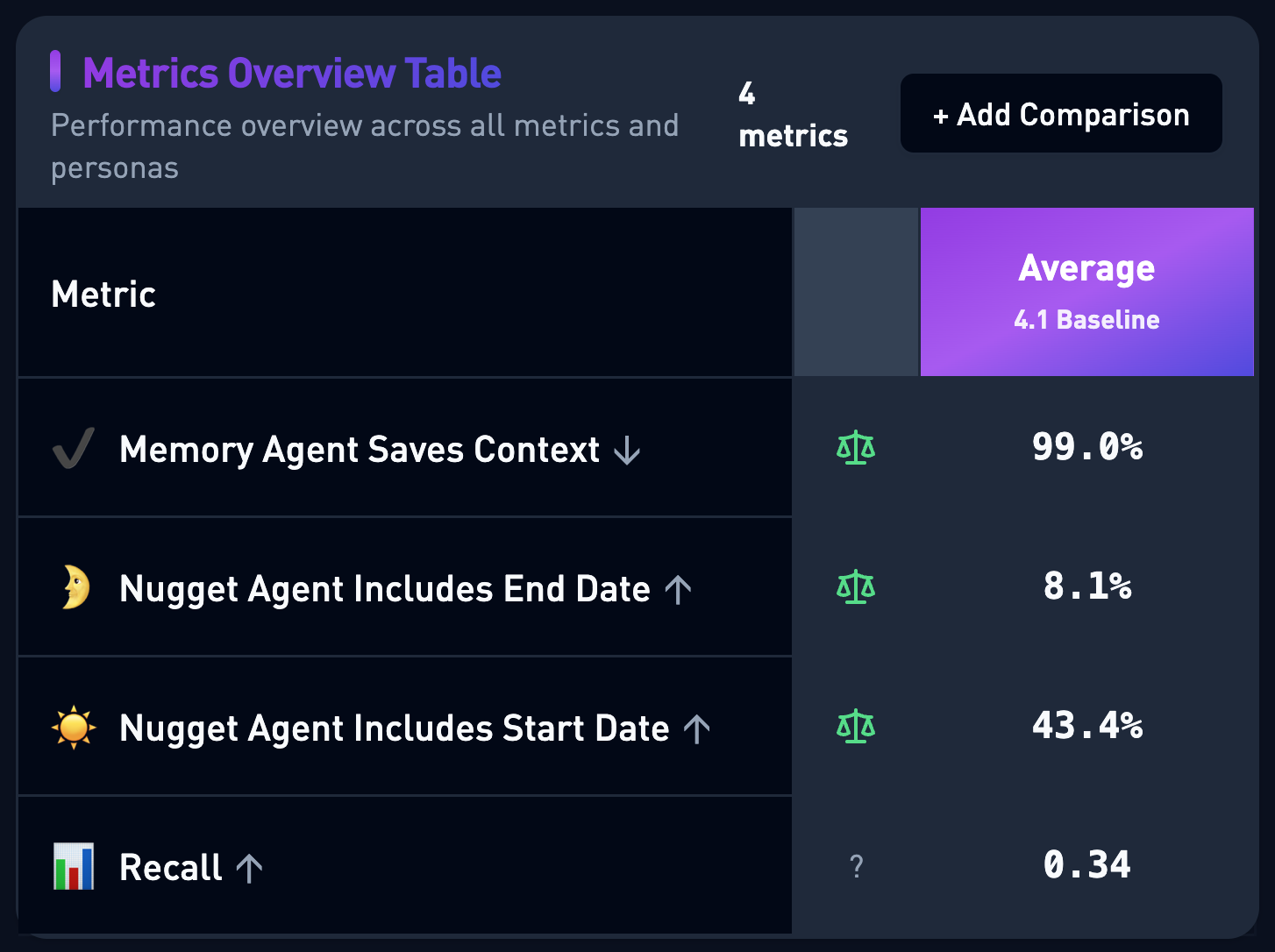
Pre-launch baseline: the Agent was remembering something 100% of the time, and not saving dates -- so memories would never expire!
| Metric | Rate | Notes |
|---|
| Did Save Context Rate | 99% | Far too aggressive! It's saving on nearly every interaction |
| Should Save Context Rate | 34% | Only 34% alignment with expected behavior |
| Include Start Date Rate | 43.4% | Room for improvement on temporal context |
| Include End Date Rate | 8.1% | Almost never setting expiration and memories accumulate indefinitely |
Iterating: When "Better" Wasn't Better
Here's where the framework proved its value. After some prompting tweaks and local tests, things felt like they were improving. Many teams would ship at this point, run an A/B test, and wait the required few days to see if metrics are improving.
At WHOOP, we run an Evaluation, and this time it caught a critical regression before it reached a single member:
| Metric | Rate | Notes |
|---|
| Did Save Context Rate | 100% | Even more aggressive after changes |
| Should Save Context Rate | 31% | Worse than baseline |
| Include Start Date Rate | 29.0% | Regressed |
| Include End Date Rate | 15.0% | One bright spot, this improved |
We thought we were improving, but the data showed otherwise. This is exactly the kind of silent regression that plagues AI deployments across the industry. Teams could ship changes that "feel right" only to discover problems weeks later through member feedback, and we want to avoid that.
Our Evaluation framework caught this in minutes rather than days to weeks. We iterated until we actually improved:
After a few more iterations, we finally got to these numbers:
| Metric | Rate | Notes |
|---|
| Did Save Context Rate | 46% | Much more selective, saving only when meaningful |
| Should Save Context Rate | 84% | Much stronger alignment with expected behavior |
| Include Start Date Rate | 37.0% | 37% of all interactions include a start date; dividing 37% by the 46% save rate means ~80% of saved nuggets include start dates |
| Include End Date Rate | 12.0% | 12% of all interactions include an end date; dividing 12% by the 46% save rate means ~26% of saved nuggets include end dates |
Beyond the numbers, careful and considerate review of individual traces showed the content of the context nuggets themselves got smarter, remembering meaningful details rather than noise.
The Outcome
We did not ship these issues to production because the Evaluation framework caught it all during development, and only after we were confident in the numbers did we roll Memory out. We've since added several more layers that make it even more robust.
Beyond Test Suites: Agent Observability
Evaluations tell you how an Agent performs when you intentionally test it. But what about the other 99% of interactions happening in production?
We extended the framework to close that gap. Our Agent Observability extends the framework beyond test suites to monitor production quality over time -- no separate tooling, no duplicated logic. This means the metrics we trust in testing are the exact same metrics monitoring production traffic. When traffic patterns shift in ways our test sets didn't anticipate, we see it in hours rather than discovering it through feedback days later. We can compare quality metrics across Agent versions before and after a rollout.
Confidence at Scale
From spreadsheets to an integrated evaluation platform to production observability, each layer compounds on the last. Evaluations catch regressions before they ship. Observability catches the ones that only surface under real-world conditions. Together, they give us something rare in AI development: confidence.
Quality is only half of it -- security is non-negotiable. Our Evaluation framework includes metrics that verify Agents correctly refuse dangerous or privacy-violating requests, and we gate deployments on those results. An Agent that gives great answers but leaks member data or ignores safety boundaries doesn't ship. Period.
This infrastructure is a strategic asset. When a new model drops, we can validate quality and safety in hours, not weeks. When a prompt change improves one metric, we catch regressions in others before they reach production. This is the discipline that separates teams who ship AI reliably from those constantly firefighting.
There's More
Evaluations and observability are just one piece of what we've built. AI Studio also includes automated Evaluation CI gates that block deployments when they indicate a potential regression. Beyond that, we have RAG quality metrics, a custom prompt templating language (HPML), reusable Snippets, Sub Agents, Goals, and more. We'll dive deeper into these in future posts.
The bottom line: Unit tests aren't enough for non-deterministic systems, but you can evaluate them rigorously. We built the infrastructure to do that at scale: 500+ Agents, 2000+ evaluations and growing. That's how we ship with confidence.
Want to build the future of health and performance with AI? WHOOP is hiring engineers, product managers, and AI researchers who are passionate about using technology to unlock human performance.