


Late last year, Google communicated with us on an observation they had with our App in the Play Store: our Android sessions were being flagged for excessive partial wake lock usage. We did not see significant impact on our build. Battery life wasn't trending in support tickets, and app reviews showed nothing unusual. But the signal was there, and we worked with Google to dig in and fix it.
At the time, we knew something was off. What we didn't know yet was which background workers were responsible, or how wake lock time was distributed across them. Finding out would make Android connectivity more robust and insights delivered more efficiently to members.
🥊 Wake Locks: 1 — WHOOP: 0. Google flags ~15% of sessions. It did not appear to affect production.
To understand why that signal mattered, it helps to know what a partial wake lock actually is.
What's a Partial Wake Lock?
A partial wake lock is an Android power management mechanism that lets an app keep the phone's CPU running while the screen is off, so important background work can finish reliably. In the WHOOP app, this can help ensure background tasks like syncing data from the strap to our servers complete even when the phone is idle. Partial wake locks are useful when they're acquired only when needed and released quickly, but if they're held too long or too often, they can keep the device out of deeper sleep states and increase background power usage.
Google tracks this in Android vitals. A session is flagged as excessive when non-exempted wake locks (see what's exempt) accumulate 2+ hours in a 24-hour period. Once that happens in more than 5% of sessions (averaged over 28 days), Play Console surfaces it as a performance signal, and as of March 2026, it can affect your app's ranking and trigger a warning on your store listing.
How We Use WorkManager
The WHOOP Android app relies on WorkManager to deliver the Always On experience: syncing data from the strap, uploading logs, running periodic firmware update checks, and more. WorkManager is Google's recommended solution for deferrable background work, and we use it extensively across the app.
We configure workers with constraints that reflect the nature of the work:
- Network connected: required for most sync tasks
- Expedited: used for firmware update checks to ensure timely delivery
Two scheduling cadences dominate our background work: short intervals for time-sensitive sync tasks, and longer intervals for non-urgent work like log uploads and periodic health checks. At any given time, a typical WHOOP session has several workers scheduled, queued, or running.
How We Investigated
We didn't have a single clear indicator. Instead, we layered several data sources and tools, progressively narrowing from "something's wrong" to "this specific code path, in this specific device state." Here's the methodology, step by step.
Step 1: Play Console + Google outreach — Confirmed the problem and gave us a starting point. Play Console showed the excessive wake lock rate (~15%) and rough timing. Google also pointed at Worker1 (syncs sensor data to our backend) and Worker2 (periodically checks for firmware updates) as the primary suspects based on their wake lock attribution data. We had a hypothesis, but needed to verify the full picture.
Step 2: Internal WorkManager metrics — Two workers stood out. We instrument every worker with run frequency, average runtime, P95 runtime, and timeout rate. Sorting by these surfaced two workers immediately: Worker1 and Worker2. Both ran more often than expected, and one was timing out at a surprisingly high rate.
Step 3: Logs — Strap disconnection as the common thread. With specific workers in mind, we looked at logs correlated with those worker runs. A clear pattern emerged: the misbehaving runs clustered around sessions where the WHOOP strap was disconnected from the phone.
Step 4: Trace tags (setTraceTag()) + Play Console wake lock dashboard — Ruling out a false lead. Worker1 had both a one-time and a periodic variant sharing the same business logic, and we suspected only one might be responsible. Adding setTraceTag() calls to distinguish between them told a different story: both variants were misbehaving equally. The bug was in the shared business logic, not the scheduling. Play Console's updated dashboard confirmed Worker1 and Worker2 as the primary drivers, and we tackled both in parallel.
Step 5: Fixed Worker1 first — Partial win. Worker1 was timing out because of a logic bug: it was waiting for an event type that, in certain device states, was never emitted.
// Worker1: before fix
override suspend fun work(): Result {
// Waits for a sync-ready event — never emitted when strap is disconnected
val event = syncEventFlow
.filter { it.type == SyncEventType.READY }
.first() // suspends indefinitely in certain device states
return syncData(event)
}
We fixed it. The excessive wake lock rate dropped by a few percentage points — a real improvement, but the rate remained elevated.
🥊 Wake Locks: 1 — WHOOP: 1. Worker1 fixed. Rate drops a few points. Fight's not over.
Step 6: Back to Google — Before pressing on, we shared our findings with Google. Their data confirmed the improvement from the Worker1 fix, and helped us see that Worker2 was the primary remaining driver.
Step 7: Continued investigation + root cause trace — With Worker1 addressed, all eyes turned to Worker2. It shared similar runtime and timeout characteristics, and the same strap-disconnection pattern from Step 3 applied. Tracing it directly made the behavior concrete and reproducible. Watching it start, run, and fail to complete when the strap was disconnected pointed us to the specific code path responsible.
The Root Cause
The problem turned out to be two-part. Worker1 had a straightforward logic bug: in certain device states, it waited for an event that was never emitted, timing out on every affected run. Worker2 was the deeper issue. When the WHOOP strap is disconnected, it would suspend indefinitely, holding a wake lock the entire time, until WorkManager's timeout killed it. Together, these accounted for the full ~15% excess: roughly 4% from Worker1, and the remaining ~11% from Worker2.
The specific pattern: Worker2 used a Kotlin StateFlow (sensorFlow) to read the current strap and sensor state. It called .filterNotNull() on the flow, then .first() to take the first non-null emission and proceed with its business logic. This is a reasonable pattern when you know the upstream will eventually emit a non-null value. But when the WHOOP strap is disconnected, the sensor value is null and stays null. There's no pending emission coming. The worker was effectively encoding "wait until the strap is connected," which is dangerous inside a WorkManager worker.
// Worker2: before fix
override suspend fun work(): Result {
return sensorFlow
.filterNotNull() // blocks here if sensor is null (strap disconnected)
.flatMapLatest { sensor ->
// business logic only runs when sensor is non-null
}
.map { Result.success() }
.first() // waits forever if upstream never emits non-null
}
That timeout is what we were seeing in our internal metrics, and those long-running sessions were what Play Console was flagging. The code wasn't buggy in the traditional sense. It worked correctly when the strap was connected. The bug was a design assumption baked in: that the prerequisite (a connected sensor) would always be available when the worker ran. It wasn't.
The Fix
The fix was conceptually simple: don't wait for prerequisites that might never arrive. Instead, check what's available right now and exit cleanly if the preconditions aren't met.
We replaced the flow subscription with a check on replayCache, a StateFlow feature that holds the most recent emission synchronously with no suspension required. If a non-null sensor value is already cached, we proceed with the business logic. If the cached value is null (meaning the strap is not currently connected), we return Result.failure() immediately and let WorkManager handle rescheduling if appropriate. No indefinite suspension. No timeout risk. The worker completes in milliseconds when the strap is disconnected, rather than waiting until WorkManager kills it.
// After: exit early when prerequisites aren't met
override suspend fun work(): Result {
return sensorFlow.replayCache
.firstOrNull()
?.let { sensor ->
businessLogic(sensor)
.map { Result.success() }
.first()
}
?: Result.failure() // exit immediately when strap is disconnected
}
The key insight: replayCache gives you the current value synchronously. If it's null, you know the strap isn't connected right now. Return early. Done in milliseconds instead of waiting until a timeout cancels the worker.
We added unit tests covering both paths explicitly. The strap-disconnected path: replayCache holds null, expect Result.failure() returned immediately. The strap-connected path: replayCache holds a valid sensor value, expect business logic to complete and return Result.success(). Both code paths now have explicit test coverage, guarding against any regression that reintroduces an indefinite wait.
The Results
The improvement was more dramatic than we expected: a 97% reduction in P95 runtime.
- Average worker runtime: ~35 seconds → ~3 seconds
- P95 runtime: ~2 minutes 27 seconds → ~4 seconds
- Excessive partial wake lock rate: ~15% → under 1%
- Timeouts and cancellations declined significantly
🥊 Final bell. WHOOP wins.
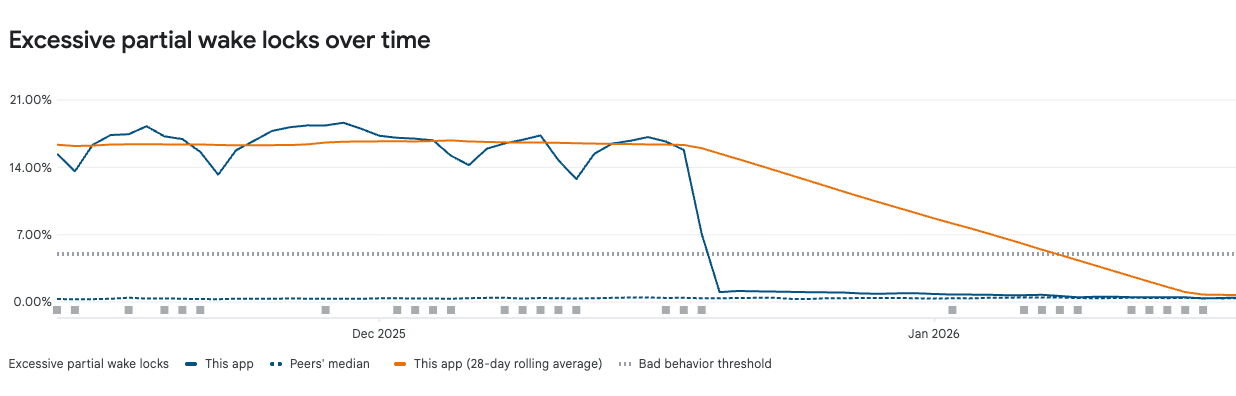
Excessive partial wake locks over time — rate dropped from ~15% to under 1% after the fix.
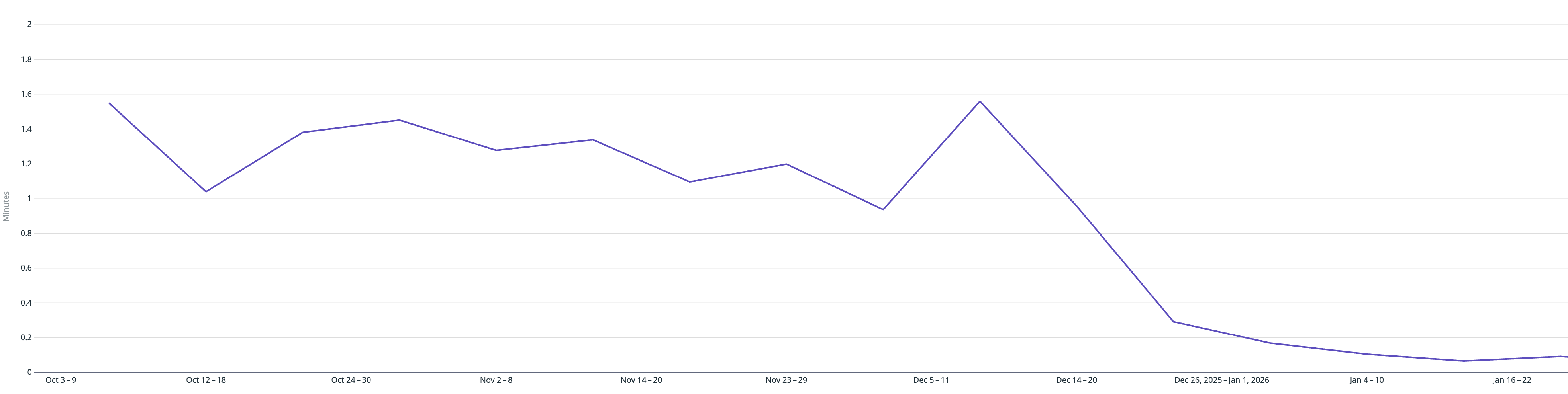
To frame the battery impact: at P95, workers were running for over 2 minutes holding a wake lock. That translates to roughly 0.3–1.3% of additional battery drain per affected session. It's the kind of thing that's easy to miss but worth catching early. (Estimates based on typical Android device power profiles; actual impact varies by device model and usage pattern.)
What We Learned
Design background workers to always have a clear exit path. If prerequisites aren't met when a worker runs, return early. Workers should not encode "wait until conditions change." That's what scheduling constraints and retry policies are for. The right question to ask when writing any worker: what happens if this resource is unavailable right now?
Internal proxy metrics (worker runtimes, timeout counts, run frequency) surface problems early. We found this before it surfaced in support tickets or reviews. That's the goal. If you're only tracking worker success/failure, you're flying blind on a whole class of performance issues.
Play Console's wake lock attribution dashboard is a key accelerator. It surfaces which specific workers are holding wake locks and how time is distributed across them. Keep your WorkManager library current — the diagnostics alone justify it.
WorkManager trace tags (setTraceTag()) are underused. Distinguishing one-time vs. periodic worker variants with separate trace tags let us confirm the root cause was in shared business logic, not scheduling configuration. That distinction matters for knowing where to look.
Write unit tests for both paths. Strap disconnected (
replayCacheholds null, expectResult.failure()) and strap connected (replayCachehas a valid value, expect business logic to complete). Explicit coverage for the unavailable-prerequisite path is what will catch a regression before it ships.
Looking Ahead
Android's background execution policies continue to tighten with each platform release. Addressing this proactively puts us in a better position for whatever comes next. The fix made Android connectivity more robust and insights delivered more efficiently to members. The investigation has since shaped how we review background work: any worker that subscribes to a flow and calls .first() without first checking current state gets a closer look.
WHOOP also collaborated with Google on a blog post covering this work, worth reading for the platform-level perspective on wake lock management and the tooling improvements they've been shipping.
A special thanks to Chris Wurts for his support throughout this investigation, and to Breanna and Alice from Google for their collaboration and guidance.
Want to build the future of health and performance with us? WHOOP is hiring engineers who care about performance, reliability, and getting the details right.