
The latest model isn't always the best model for every use case.
Before we can chat about GPT-5.1, we have to talk about GPT-5. When GPT-5 dropped, we were excited. Our evals showed GPT-5 was clearly more intelligent and we quickly rolled it out for our high intelligence agents and high-reasoning tasks where that capability shines. But for our low-latency chat, GPT-5's minimal reasoning mode actually underperformed GPT-4.1 on our evals. Different use cases, different results. Our per use case evaluations allowed us to immediately make these determinations.
We shared those findings directly with OpenAI in our weekly call with them and at Dev Day. At DevDay, we spent time chatting with their engineers walking through our eval results and discussing what we needed for latency-sensitive applications like chat. That collaboration mattered.
GPT-5.1 shipped with a new none reasoning mode that addressed exactly what we'd flagged. We ran our evals again, and this time the results were different. Within a week, we had validated it against over 4,000 test cases, A/B tested in production, and rolled it out to everyone.
22% faster responses. 24% more positive feedback. 42% lower costs.
Here's exactly what we evaluated, what we found, and why we shipped.
Evals First: Validating GPT-5.1
Before touching production, we ran our full evaluation suite against GPT-5.1, comparing it to our GPT-4.1 baseline for our core chat use case. Here's what we found:
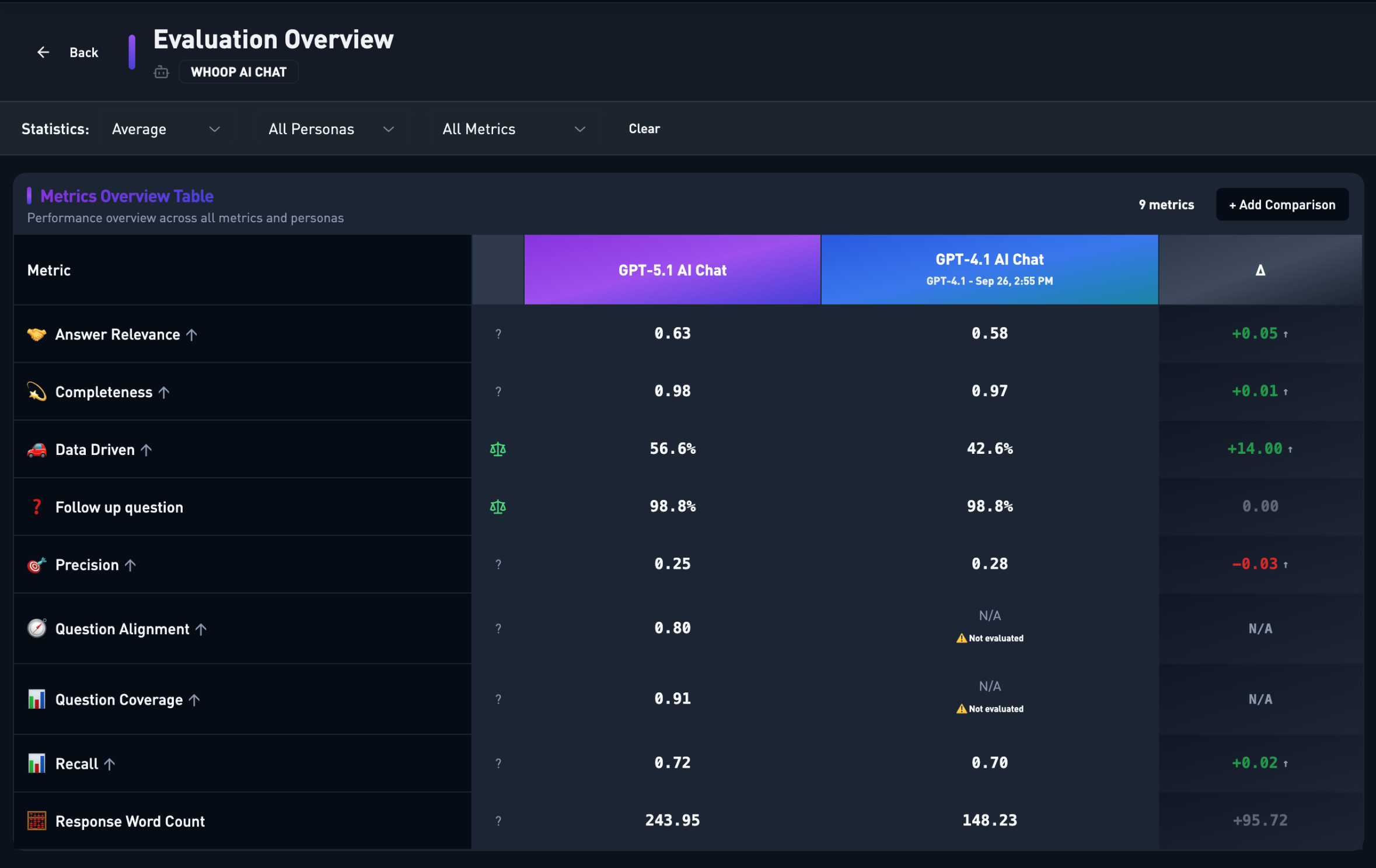
Our internal evaluation dashboard comparing GPT-4.1 (baseline) against GPT-5.1 across over 4,000 test cases
| Metric | GPT-4.1 Baseline | GPT-5.1 | Change |
|---|---|---|---|
| Answer Relevance | 0.58 | 0.63 | +0.05 |
| Completeness | 0.97 | 0.98 | +0.01 |
| Data Driven | 42.6% | 56.6% | +14.00 |
| Recall | 0.70 | 0.72 | +0.02 |
| Follow-up Question | 98.8% | 98.8% | 0.00 |
| Precision | 0.28 | 0.25 | -0.03 |
| Response Word Count | 148.23 | 243.95 | +95.72 |
The headline numbers were impressive: Answer Relevance up ~5%, Data-Driven responses up 14 percentage points, and Recall improved by 2 points. GPT-5.1 was consistently surfacing more personalized health insights. The "Data Driven" metric measures how often responses incorporate actual individualized data rather than generic advice—jumping from 42.6% to 56.6% is a game-changer for personalized coaching.
What's driving that Data Driven jump? Significantly higher (and more accurate) tool call usage, primarily focused on AIQL queries—our internal query language for pulling individualized data like sleep, strain, and recovery. More data queries mean more personalized context in every response.
We measured answer relevance, recall, data usage, tool accuracy, and conversation dynamics. There are trade-offs: GPT-5.1 shows a slightly lower precision score (0.25 vs 0.28) and produces somewhat longer responses, even after light prompt tuning to reduce verbosity. But those extra tokens are doing useful work. The model infers intent better and explains why, not just what. The added detail shows up primarily in complex coaching conversations that deserve deeper explanation, not in simple one-off questions. When we reviewed individual traces, the trade-off was clearly worth it.
The Real Test: Production
Evals told us GPT-5.1 was ready. But evals only tell part of the story—the real test is always production.
We rolled GPT-5.1 out to roughly 10% of production load as a controlled A/B test, monitoring latency, tool usage, cache hit rates, user feedback, and token spend. The live data told an even better story than our evals predicted:
22% Faster Responses
Here's what surprised us: despite providing more comprehensive answers and using tools more thoroughly, GPT-5.1's time to first token dropped significantly. This defies the usual trend where "smarter" models are slower.
| Percentile | GPT-4.1 | GPT-5.1 | Improvement |
|---|---|---|---|
| p50 (median) | 1.53s | 0.98s | 36% faster |
| p90 | 2.88s | 1.96s | 32% faster |
| p99 | 5.83s | 4.55s | 22% faster |
The median response now starts streaming in under a second. The model itself is faster: 34% higher token velocity (98/s → 131/s) and 18% faster time-to-first-token (841ms → 688ms). That's not our optimization. It's a better model on better infrastructure.
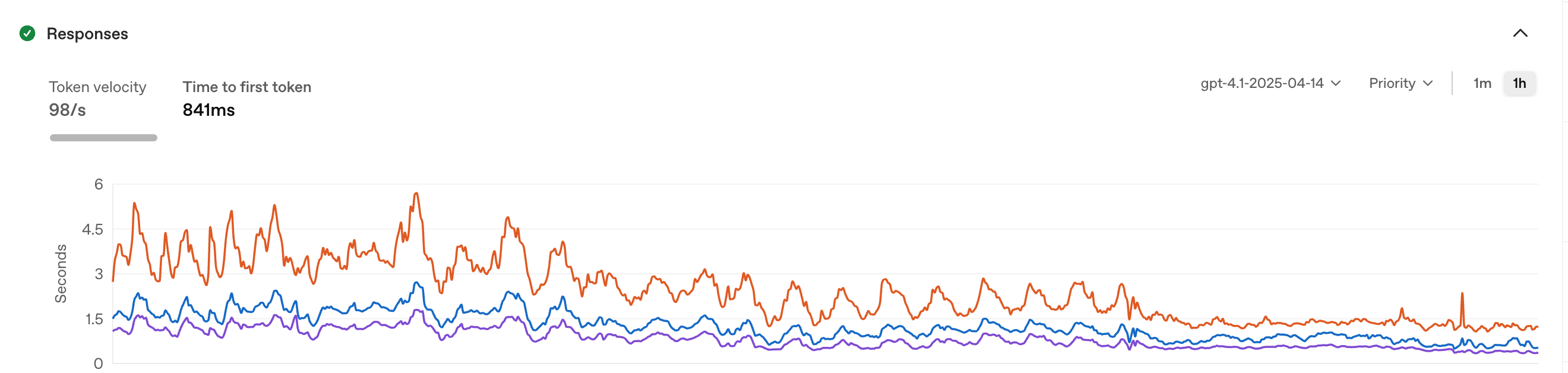
GPT-4.1 baseline: 98 tokens/sec, 841ms time to first token
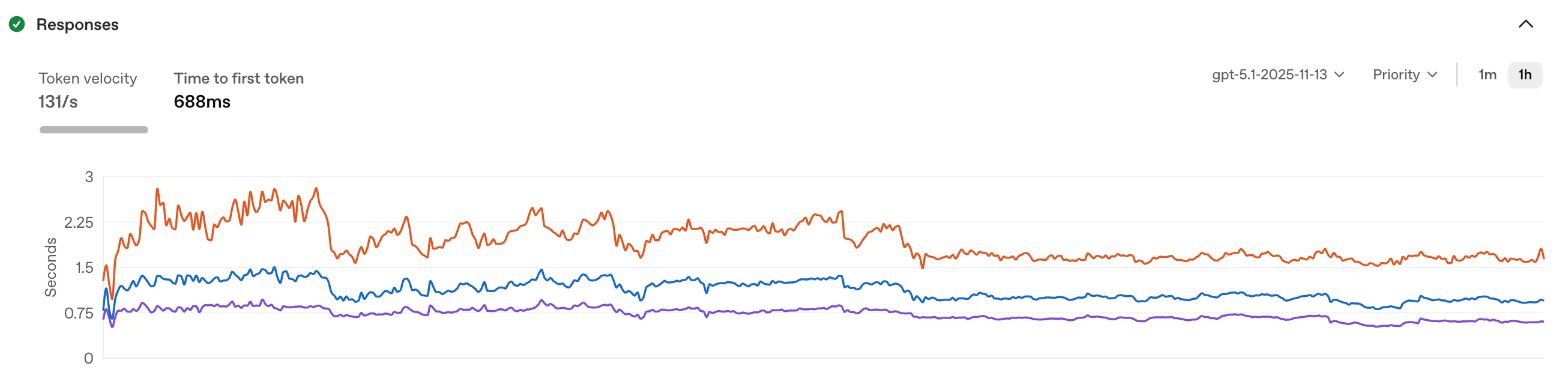
GPT-5.1: 131 tokens/sec, 688ms time to first token
Amplified by Better Caching
On top of the model improvements, we saw dramatically improved caching efficiency.
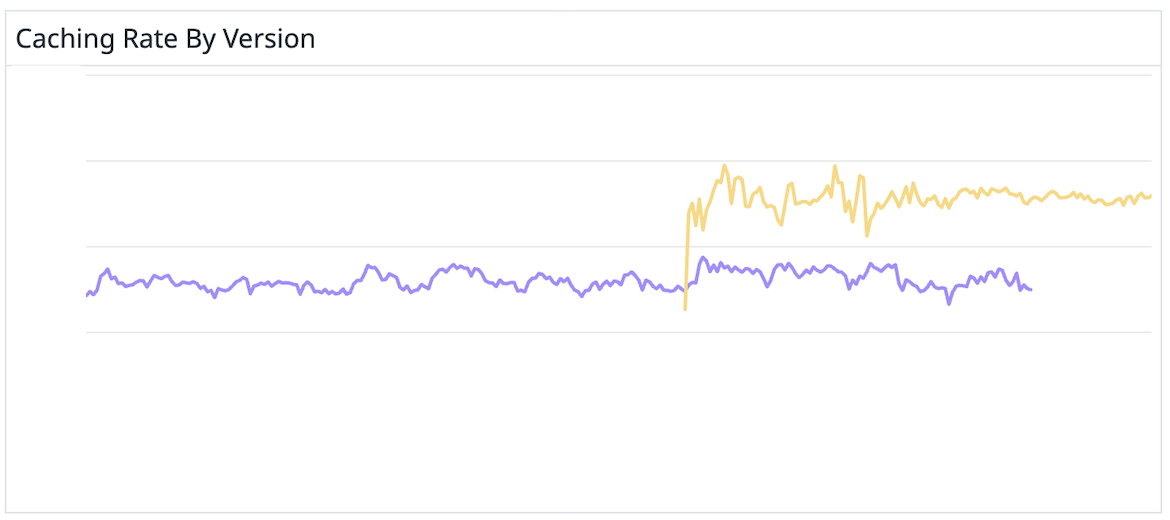
Cache hit rates improved by 50% with GPT-5.1
OpenAI's improved GPT-5.1 infrastructure meant a 50% improvement in cache hit rates. We didn't change anything on our end; the model just automatically has a higher cache hit rate for us.
Cached tokens are 10x cheaper, and our coaching experience has an extremely high input-to-output token ratio—lots of context for every answer. That combination makes caching efficiency a massive cost lever.
24% More Positive Feedback
Users prefer 5.1 over 4.1 with a 24% increase in positive feedback (thumbs up) and a corresponding decrease in negative feedback. Faster responses plus better answers equals deeper engagement.
42% Lower Token Costs
If GPT-5.1 produces wordier responses (+96 words on average), how did costs go down? That 50% caching improvement. Serving significantly more requests from cache at 10x lower cost, combined with cheaper overall prices than 4.1, drove lower total cost.
At scale, these efficiency gains translate to significant savings we can reinvest into building better AI experiences.
From 10% to 100% Rollout
Based on these results, we rolled GPT-5.1 out to 100% of production traffic. The metrics have held steady, confirming what our evals and A/B test predicted.
What We Learned
A year ago, evaluating a new model would have taken weeks. Now we can eval in hours and ship the same day.
When GPT-5 came out, we knew within hours it wasn't the right fit for low-latency chat. When GPT-5.1 came out, we knew within hours it was. That speed comes from investing in use-case-specific evaluation infrastructure. As model release cadence accelerates, this kind of rapid validation isn't optional. It's how you lead.
Our partnership with OpenAI made this launch better and helped make 5.1 the model we needed. Our in-house eval framework gave us the ability to validate any new model against our specific use cases, catch regressions before they hit production, and ship with confidence.
With 56.6% data-driven responses (up from 42.6%), faster responses that make coaching feel like a conversation, and lower costs we can reinvest into building better AI experiences.
If you want more context on how we build and ship agents at WHOOP, check out our earlier post on AI Studio, "From Idea To Agent In Less Than Ten Minutes".
What's Next
We're not done. The ultimate metric isn't eval scores or even user feedback. It's whether better AI responses lead to better health outcomes. That's where we're headed.
The bottom line: We shipped a new model in a week, validated by our custom eval framework. 22% faster responses, 24% more positive feedback, 42% lower costs. That's what rapid iteration looks like.
Want to build the future of health and performance with AI? WHOOP is hiring engineers, product managers, and AI researchers who are passionate about using technology to unlock human performance.